Nuclei CUDA - duševne uvedomelý skalárne enumeračné bloky na video čipoch NVIDIA, začať z G80 (GeForce 8 xxx, Tesla C-D-S870, FX4/5600 , 360 mil). Samotné čipy sú podobné architektúry. Pred prejavom spol NVIDIA tak sa horlivo chopil rozrobka vlasnyh procesorov Séria Tegra, tiež založený na RISC architektúra. Dosvid práca s týmito architektúrami je už teraz skvelá.
CUDA jadro pomstiť sa na sebe jeden vektorі jeden skalár jednotka, ako v jednom hodinovom cykle, počítanie jedným vektorom a jednou skalárnou operáciou, prenesením výpočtu na ďalší multiprocesor alebo na ďalšie spracovanie. Pole stoviek a tisícok takýchto jadier predstavuje značné množstvo tvrdosti a môže zvíťaziť nad rôznymi úlohami v lade, v závislosti od zrejmosti softvéru skladby. Zastosuvannya môžu byť rôzne: dekódovanie video streamu, zrýchlená 2D/3D grafika, kalkulácia nízkych nákladov, špecializovaná matematická analýza atď.
Popíjajte často, zjednotení profesionálny karty nvidia Teslaі NVIDIA Quadro, є chrbtica moderných superpočítačov
CUDA- jadrá nepoznali žiadne výrazné zmeny od hodín G80 a potom zvýšte ich množstvo (spolu s menšími blokmi ROP, textúrne jednotky atď.) efektívnosť paralelných interakcií jeden po druhom (násobenie modulov Giga vlákno).

Napríklad:
GeForce
Jadrá GTX 460 - 336 CUDA
Jadrá GTX 580 - 512 CUDA
8800GTX - 128 jadier CUDA
Počet stream procesorov ( CUDA), produktivita počtov shaderov sa prakticky proporcionálne zvyšuje (s rovnakým nárastom počtu a ďalších prvkov).
Počnúc čipom GK110(NVidia GeForce GTX 680) CUDA jadrá teraz nemusia zdvojnásobovať frekvenciu, ale namiesto toho využívajú ostatné bloky čipu. Počet osôb bol zvýšený o cca. tri krát u starších generácií G110.
І priradenia na preklad do kódu hostiteľa (hlava, kód kľúča) a kódu zariadenia (hardvérový kód) (súbory s príponami.cu) do objektových súborov, príslušenstva v procese kompilácie konečného programu alebo knižnice v akomkoľvek programovacom prostredí, napríklad NetBeans.
V architektúre CUDA víťazí pamäťový model mriežky, klastrový model tokov a inštrukcie SIMD. Za grafické karty nVidia nie sú len vysokovýkonné grafické karty, ale aj iné vedecké účty. Vcheni ta doslіdniki široko vikorovuyu CUDA in iných oblastiach, vrátane astrofyziky, výpočtovej biológie a chémie, modelovania dynamiky riek, elektromagnetických interakcií, počítačovej tomografie, seizmickej analýzy a mnohých ďalších. CUDA má schopnosť pripojiť sa k programom, ktoré používajú OpenGL a Direct3D. CUDA je multiplatformový softvér pre operačné systémy ako Linux, Mac OS X a Windows.
22. marca 2010 nVidia vydala CUDA Toolkit 3.0, čo je oživenie podpory OpenCL.
Vlastníctvo
Platforma CUDA sa prvýkrát objavila na trhu s uvedením ôsmej generácie čipu NVIDIA G80 a stala sa prítomnou vo všetkých pripravovaných sériách grafických čipov, ktoré sa nachádzajú v rodinách rýchlo rastúcich GeForce, Quadro a NVidia Tesla.
Prvý zo série, ktorý podporuje CUDA SDK, G8x, je malý 32-bitový vektorový procesor s jednoduchou presnosťou, ktorý podporuje CUDA SDK ako API (CUDA podporuje typ double movie Ci, presnosť proteo je znížená na 32- bit s pohyblivou rádovou čiarkou). Nižšie procesory GT200 môžu podporovať 64-bitovú presnosť (iba pre SFU), ale výkon je výrazne vyšší, nižší pre 32-bitovú presnosť (cez tie existujú iba dve SFU na multiprocesor na streamovanie kože a skalárne procesory - všetky). Grafický procesor organizuje hardvérovú bohatosť toku, čo vám umožňuje využívať všetky zdroje grafického procesora. Týmto spôsobom sa objavuje perspektíva presunutia funkcií fyzickej skratky do grafickej (príklad implementácie - nVidia PhysX). Taktiež existujú široké možnosti využitia grafického nastavenia počítača na skladací negrafický výpočet: napríklad pri výpočte biológie a iných vedeckých trikov.
Perevagi
Alternatívne s tradičným prístupom k organizácii výpočtu globálneho uznania pre dodatočné možnosti grafických API môže architektúra CUDA vyhrať aj v tejto galérii:
Výmena
- Všetky funkcie, ktoré sú zobrazené na rozšírení, nepodporujú rekurziu (vo verzii CUDA Toolkit 3.1 podporujú indikátory rekurzie) a môžu fungovať iné výmeny
Vylepšenia GPU a vylepšenia grafiky
Preklad doplnku v podobe vybavenia s podporou Nvidie z deklarovanej novej podpory technológie CUDA je zobrazený na oficiálnych stránkach Nvidie: CUDA-Enabled GPU Products (anglicky).
V skutočnosti bude v tejto hodine na trhu hardvéru pre PC podpora technológie CUDA zabezpečená pokrokovými periférnymi zariadeniami:
| Verzia špecifikácie | GPU | Video karty |
|---|---|---|
| 1.0 | G80, G92, G92b, G94, G94b | GeForce 8800GTX/Ultra, 9400GT, 9600GT, 9800GT, Tesla C/D/S870, FX4/5600, 360M, GT 420 |
| 1.1 | G86, G84, G98, G96, G96b, G94b, G94b, G92b, G92b | GeForce 8400GS/GT, 8600GT/GTS, 8800GT/GTS, 9600 GSO, 9800GTX/GX2, GTS 250, GT 120/30/40, FX 4/570, 3/580, 107/370/3 /770M, 16/17/27/28/36/37/3800M, NVS420/50 |
| 1.2 | GT218, GT216, GT215 | GeForce 210, GT 220/40, FX380 LP, 1800M, 370/380M, NVS 2/3100M |
| 1.3 | GT200, GT200b | GeForce GTX 260, GTX 275, GTX 280, GTX 285, GTX 295, Tesla C/M1060, S1070, Quadro CX, FX 3/4/5800 |
| 2.0 | GF100, GF110 | GeForce (GF100) GTX 465, GTX 470, GTX 480, GTX140 500 |
| 2.1 | GF104, GF114, GF116, GF108, GF106 | GeForce 610M, GT 430, GT 440, GTS 450, GTX 460, GTX 550 Ti, GTX 560, GTX 560 Ti, 500M, Quadro 600, 2000 |
| 3.0 | GK104, GK106, GK107 | GeForce GTX 690, GTX 680, GTX 670, GTX 660 Ti, GTX 660, GTX 650, GeForce GTX 675MX, GeFor 6 GeForce GT 645M, GeForce GT 640M |
| 3.5 | GK110 |
|
|
|
|
|
- Modely Tesla C1060, Tesla S1070, Tesla C2050/C2070, Tesla M2050/M2070, Tesla S2050 umožňujú vykonávať výpočty na GPU s premenlivou presnosťou.
Vlastnosti a špecifikácie rôznych verzií
| Podpora funkcií (neuvedené funkcie sú podporované pre všetky výpočtové možnosti) |
Výpočtová schopnosť (verzia) | ||||
|---|---|---|---|---|---|
| 1.0 | 1.1 | 1.2 | 1.3 | 2.x | |
32-bitové slová v globálnej pamäti |
Ahoj | Takže | |||
hodnoty s pohyblivou rádovou čiarkou v globálnej pamäti |
|||||
| Celočíselné atómové funkcie fungujúce na 32-bitové slová v zdieľanej pamäti |
Ahoj | Takže | |||
| atomicExch() pracujúci na 32-bit hodnoty s pohyblivou rádovou čiarkou v zdieľanej pamäti |
|||||
| Celočíselné atómové funkcie fungujúce na 64-bitové slová v globálnej pamäti |
|||||
| Funkcie warp hlasovania | |||||
| Operácie s pohyblivou rádovou čiarkou s dvojitou presnosťou | Ahoj | Takže | |||
| Atómové funkcie pracujúce na 64-bit celočíselné hodnoty v zdieľanej pamäti |
Ahoj | Takže | |||
| Atómová adícia s pohyblivou rádovou čiarkou funguje 32-bitové slová v globálnej a zdieľanej pamäti |
|||||
| _ballot() | |||||
| _threadfence_system() | |||||
| _synctreads_count(), _syncthreads_and(), _syncthreads_or() |
|||||
| Funkcie povrchu | |||||
| 3D mriežka bloku závitov | |||||
| Technické špecifikácie | Výpočtová schopnosť (verzia) | ||||
|---|---|---|---|---|---|
| 1.0 | 1.1 | 1.2 | 1.3 | 2.x | |
| Maximálny rozmer mriežky závitových blokov | 2 | 3 | |||
| Maximálny rozmer x, y alebo z mriežky závitových blokov | 65535 | ||||
| Maximálny rozmer závitového bloku | 3 | ||||
| Maximálny rozmer x alebo y bloku | 512 | 1024 | |||
| Maximálny z-rozmer bloku | 64 | ||||
| Maximálny počet vlákien na blok | 512 | 1024 | |||
| Veľkosť osnovy | 32 | ||||
| Maximálny počet rezidentných blokov na jeden multiprocesor | 8 | ||||
| Maximálny počet rezidentných warps multiprocesoru | 24 | 32 | 48 | ||
| Maximálny počet rezidentných vlákien na multiprocesor | 768 | 1024 | 1536 | ||
| Počet 32-bitových registrov pre multiprocesor | 8 tis | 16 tis | 32 tis | ||
| Maximálne množstvo zdieľanej pamäte na jeden multiprocesor | 16 kB | 48 kB | |||
| Počet bánk zdieľanej pamäte | 16 | 32 | |||
| Množstvo lokálnej pamäte na vlákno | 16 kB | 512 kB | |||
| Konštantná veľkosť pamäte | 64 kB | ||||
| Pracovná súprava vyrovnávacej pamäte na multiprocesor pre stálu pamäť | 8 kB | ||||
| Pracovná súprava vyrovnávacej pamäte na multiprocesor pre pamäť textúr | V závislosti od zariadenia, medzi 6 KB a 8 KB | ||||
| Maximálna šírka pre 1D textúru |
8192 | 32768 | |||
| Maximálna šírka pre 1D textúru referencia viazaná na lineárnu pamäť |
2 27 | ||||
| Maximálna šírka a počet vrstiev pre referenciu 1D vrstvenej textúry |
8192 x 512 | 16384 x 2048 | |||
| Maximálna šírka a výška pre 2D odkaz na textúru viazaný na lineárna pamäť alebo pole CUDA |
65536 x 32768 | 65536 x 65535 | |||
| Maximálna šírka, výška a počet vrstiev pre referenciu 2D vrstvenej textúry |
8192 x 8192 x 512 | 16384 x 16384 x 2048 | |||
| Maximálna šírka, výška a hĺbka pre referenciu 3D textúry viazanú na lineárnu pamäť alebo pole CUDA |
2048x2048x2048 | ||||
| Maximálny počet textúr, ktoré môžu byť viazané na jadro |
128 | ||||
| Maximálna šírka pre 1D povrch odkaz viazaný na pole CUDA |
nie podporované |
8192 | |||
| Maximálna šírka a výška pre 2D povrchová referencia viazaná na pole CUDA |
8192 x 8192 | ||||
| Maximálny počet plôch, ktoré môžu byť viazané na jadro |
8 | ||||
| Maximálny počet pokynov na jadro |
2 milióny | ||||
zadok
CudaArray* cu_array; textúra< float , 2 >tex; // Pridelenie poľa cudaMalloc( & cu_array, cudaCreateChannelDesc< float>(), šírka výška); // Kopírovanie údajov obrázka do poľa cudaMemcpy( cudaMemcpy, obrázok, šírka* výška, cudaMemcpyHostToDevice) ; // Naviazať pole na textúru cudaBindTexture( tex, cu_array) ; // Spustite jadro dim3 blockDim(16, 16, 1); dim3 gridDim(šírka/blokDim.x, výška/blokDim.y, 1); jadro<<< gridDim, blockDim, 0 >>> (d_odata, sirka, vyska); cudaUnbindTexture(tex); __global__ void kernel(float * odata, int výška, int šírka) ( unsigned int x = blockIdx.x * blockDim.x + threadIdx.x ; unsigned int y = blockIdx.y * blockDim.y + threadIdx.y ; float texfetch( tex, x, y);odata[y* šírka+ x] = c;
Importovať pycuda.driver ako drv import numpy drv.init() dev = drv.Device(0) ctx=dev.make_context() mod=drv.SourceModule( """ __global__ void multiply_them(float *dest, float *a, float *b) ( const int i = threadIdx.x; dest[i] = a[i] * b[i]; ) """) multiply_them = mod.get_function ("multiply_them" ) a = numpy.random .randn (400 ) .astype (numpy.float32 ) b = numpy.random .randn (400 ) .astype (numpy.floatthem (a) drvply_ .Out (dest) , drv.In (a) , drv.In (b) , block= (400 , 1 , 1 ) ) print dest-a*b
CUDA ako predmet na univerzitách
Začiatkom roka 2009 je softvérový model CUDA nasadený na 269 univerzitách po celom svete. V Rusku sa prvé kurzy CUDA vyučujú na polytechnickej univerzite v Petrohrade, Jaroslavľská štátna univerzita pomenovaná po. P. G. Demidov, Moskovskij, Nižný Novgorod, Petrohrad, Tverskoje, Kazaň, Novosibirsky, Novosibirsky Holden Technická univerzita Permských UNIVITIT, UNIVITITITIONAL MITENENTY INITY ONITYAS. Bauman, RKhTU im. Mendelev, Medziregionálne superpočítačové centrum Ruskej akadémie vied, . Okrem toho začiatkom roku 2009 bolo oznámené začatie práce prvého vedeckého a osvetľovacieho centra v Rusku „Paralelný výpočet“, ktorý bol usporiadaný v meste Dubna.
Na Ukrajine sa kurzy o CUDA čítajú v Kyjevskom inštitúte pre systémovú analýzu.
Posilannya
Oficiálne zdroje
- CUDA Zone (rusky) - oficiálna stránka CUDA
- CUDA GPU Computing (anglicky) - oficiálne webové fóra venované výpočtom CUDA
Neoficiálne zdroje
Tomov hardvér- Dmitro Čekanov. nVidia CUDA: poplatky za grafické karty alebo smrť CPU? . Tomov hardvér (22. september 2008).
- Dmitro Čekanov. nVidia CUDA: testovanie GPU pre bežný trh. Tomov hardvér (utorok 19. 2009).
- Oleksij Berillo. NVIDIA CUDA - negrafické výpočty na grafických procesoroch. Časť 1. iXBT.com (23. september 2008). Archivované 4. februára 2012. Revidované 20. septembra 2009.
- Oleksij Berillo. NVIDIA CUDA - negrafické výpočty na grafických procesoroch. Časť 2. iXBT.com (22. júla 2008). - Aplikujte náplasť NVIDIA CUDA. Archivované 4. februára 2012. Revidované 20. septembra 2009.
- Boreskov Oleksij Viktorovič. Základy CUDA (20. september 2009). Archivované 4. februára 2012. Revidované 20. septembra 2009.
- Volodymyr Frolov.Úvod do technológie CUDA. časopis Merezhevy" Počítačová grafikaže multimédiá“ (19. 12. 2008). Archivované 4. februára 2012. Revidované 28. júna 2009.
- Igor Oskolkov. NVIDIA CUDA je cenovo dostupná vstupenka do sveta veľkých čísel. Počítače (30. apríla 2009). Získané 3. mája 2009.
- Volodymyr Frolov.Úvod do technológie CUDA (1. september 2009). Archivované 4. februára 2012. Revidované 3. apríla 2010.
- GPGPU.ru. Wikoristannya videokarty na výpočet
- . Centrum paralelných výpočtov
Poznámky
Div. tiež
| Nvidia | ||||||
|---|---|---|---|---|---|---|
| Grafický spracovateľov |
| |||||
Technológia CUDA
Volodymyr Frolov,[e-mail chránený]
Abstraktné
Článok hovorí o technológii CUDA, ktorá umožňuje programátorovi hacknúť grafické karty ako konkrétnejšie číslo. Nástroje odvodené od Nvidie vám umožňujú písať programy grafického procesora (GPU) v podskupinách C++. To pomôže programátorovi s potrebou používať shadery a pochopiť proces robotického grafického potrubia. V článku je predstavená aplikácia programovania s alternatívami CUDA a rôzne metódy optimalizácie.
1. Úvod
Vývoj počítacích technológií zostáva desiatky rokov rýchlym tempom. Podlahy sú shvidky, ale zároveň predajcovia procesorov prakticky prešli na takzvanú "silicon deaf kuta". Nestrymne rostannia frekvencia hodín nemožným z málo závažných technologických dôvodov.
Preto všetky dnešné vinohrady počítacie systémy choďte na väčší počet procesorov a jadier, ale nezvyšujte frekvenciu jedného procesora. Počet jadier centrálnej procesorovej jednotky (CPU) pokročilé systémy Teraz je už 8.
Ďalším dôvodom je zjavne nízka rýchlosť práce operačná pamäť. Ako keby procesor nepracoval rýchlo, v úzkych priestoroch, ako ukazuje prax, nejde o aritmetické operácie, ale skôr o nedostatok vyrovnávacej pamäte.
Avšak čudovať sa smrti grafické procesory GPU (Graphics Processing Unit), potom existovala cesta k paralelizmu oveľa skôr. Súčasné grafické karty, napríklad GF8800GTX, môžu mať až 128 procesorov. podobné systémy pri dobrom naprogramovaní môžu byť ešte výraznejšie (obr. 1).
Ryža. 1. Počet operácií s pohyblivou rádovou čiarkou pre CPU a GPU
Ak by sa prvé grafické karty práve objavili na predaj, smrad by bol jednoduchý (spolu s centrálnym procesorom) vysokošpecializovanými rozšíreniami, ktoré boli určené na to, aby procesor vyradili z vizualizácie údajov z dvoch svetov. S rozvojom herného priemyslu a objavením sa takých triviálnych hier ako Doom (obr. 2) a Wolfenstein 3D (obr. 3) sa vinyl vyžaduje 3D vizualizáciu.


Bábätká 2.3. Hry Doom a Wolfenstein 3D
Spoločnosť 3Dfx vytvorila prvé grafické karty Voodoo, (1996) a do roku 2001 v GPU iba implementáciu fixácie súboru operácií na vstupných dátach.
Shadery sa objavili pre programátorov bez možnosti výberu vizualizačných algoritmov a zvýšenej flexibility malé programy, ktoré sú označené grafickou kartou pre vrchol kože alebo pixel kože. Ich úlohy zahŕňali transformácie cez vrcholy a tieňovanie-zosvetlenie v bodoch, napríklad pre model Phong.
Občas sa shadery zbavili aj silného vývoja, keď pochopili, že smrady boli vyvinuté pre vysokoškolské vzdelávanie a špecializačné úlohy trivimerových transformácií a rozpisov. Súčasne s vývojom GPU vo viacúčelových bohatých procesorových systémoch sú filmové shadery preplnené vysokými špecializáciami.
Je možné porovnať s mojím FORTRAN k tomu, že smradi, ako FORTRAN, boli prvé, ale boli uznané za vyrishennya iba jeden typ úlohy. Shadery nie sú vhodné na zdokonaľovanie akýchkoľvek iných úloh, krim triviálne transformácie a rasterizácie, ako FORTRAN, nevhodné na dokončenie úlohy, nesúvisiace s numerickými rozrahunki.
Dnes je trendom netradičné grafické karty na vizualizáciu pri skriniach kvantovej mechaniky, kusovej inteligencie, fyzických rekonštrukcií, kryptografie, fyzikálne správnej vizualizácie, rekonštrukcie z fotografií, identifikácie. Qi zavdannya neopatrne vibrovala na hraniciach grafických API (DirectX, OpenGL), čriepky qi API vytvorili iní zastosuvania.
Rozvoj všeobecného programovania na GPU (General Programming on GPU, GPGPU) logicky viedol k ospravedlneniu technológií zameraných na širšiu oblasť výroby, nižšiu rasterizáciu. Výsledkom je, že Nvidia vytvorila technológiu Compute Unified Device Architecture (alebo skrátene CUDA) a ATI, ktorá súťaží, vytvorila technológiu STREAM.
Treba poznamenať, že v čase písania tohto článku bola technológia STREAM výrazne naklonená vývoju CUDA a to tu nie je vidieť. Zameriavame sa na technológiu CUDA - GPGPU, ktorá umožňuje písať programy vo viacerých C++ filmoch.
2. Hlavný rozdiel medzi CPU a GPU
Pozrime sa stručne na podrobnosti o rozdieloch medzi regiónmi a špecifických vlastnostiach centrálneho procesora a grafickej karty.
2.1. možnosti
CPU kopa príloh na vykonanie hlavného plánu a vyťaženie pamäte, čo je vhodne riešené. Programy na CPU je možné sťahovať bez prerušenia do stredu lineárnej alebo homogénnej pamäte.
Pre GPU to nie je zlé. Ako viete, po prečítaní tohto článku môže CUDA vidieť 6 druhov pamäte. Môžete čítať z akéhokoľvek stredu, fyzicky dostupného, ale zapisovať - nie do stredu. Dôvod spočíva v tom, že GPU je v každom prípade špecifický doplnok, uznávame ho na špecifické účely. Tse obezhennya zaprovadzhennja pre zbіlshennya svydkostі roboty singhnyh algogorіvіv і zvіzhennya vartosti і obladannya.
2.2. Švédsky kód pamäte
Rovnakým problémom viacerých výpočtových systémov je, že pamäť je efektívnejšia ako procesor. Hackeri CPU istým spôsobom porušujú vyrovnávaciu pamäť. Väčšinu času sa posun pamäte vykonáva v superoperačnej alebo vyrovnávacej pamäti, ktorá pracuje na frekvencii procesora. Tse vám umožňuje ušetriť hodinu so smrťou, ktorá je najčastejšie víťazná, a zavantazhit procesor najlepším možným spôsobom.
S úctou, pre programátora sú vyrovnávacie pamäte prakticky jasné. Rovnako ako pri čítaní, tak aj pri zápise sa dáta nepreberajú raz do operačnej pamäte, ale prechádzajú cez cache. Dovoľte mi, zokrema, rýchlo prečítať význam dňa po vstupe.
Na GPU (tu môžete použiť grafické karty GF 8. série) sú tiež dôležité vyrovnávacie pamäte, ale mechanizmus nie je taký tvrdý ako na CPU. Prvým spôsobom je zarábanie na plnej posadnutosti typmi pamäte, ale iným spôsobom sa cache cvičia iba z čítania.
Na GPU je viac než dosť času na to, aby ste nezabudli zaplatiť za ďalšie paralelné výpočty. Zatiaľ jeden zavdannya kontroluje údaje, pratsyut іnshі, pripravený na výpočet. Toto je jeden z hlavných princípov CUDA, ktorý vám umožňuje výrazne zvýšiť produktivitu systému ako celku.
3. CUDA jadro
3.1. Prietokový model
Numerická architektúra CUDA je založená na koncepciijeden tím pre anonymné údaje(Single Instruction Multiple Data, SIMD) viacprocesorový.
Dá sa využiť koncept SIMD, že jedna inštrukcia umožňuje naraz zbierať anonymné dáta. Napríklad príkaz addps v Procesory Pentium 3 a novšie modely Pentium umožňujú naraz pridávať 4 čísla s plávajúcou desatinnou čiarkou s jednoduchou presnosťou.
Multiprocesor je viacjadrový SIMD procesor, ktorý má na všetkých jadrách iba jednu inštrukciu. Vzhľad multiprocesorového jadra nie je skalárny, takže. nepodporuje vektorové operácie čistým spôsobom.
Pred Timom, ako pokračovať, predstavíme pár stretnutí. Je príznačné, že pod prílohou a hostiteľom týchto štatistík to nie sú tie, pred ktorými volala väčšina programátorov. Takéto výrazy budeme používať, aby sme sa vyhli rozdielom v dokumentácii CUDA.
Pod zariadením (zariadením) je v našom článku rozumný grafický adaptér, ktorý podporuje ovládač CUDA alebo iné špecializácie príloh, priradenia pre programovanie programov, ktoré používajú CUDA (napríklad NVIDIA Tesla). V našom článku môžeme vidieť, že GPU je menej ako logické vlastníctvo, jedinečné pre konkrétne detaily implementácie.
Hostiteľ (hostiteľ) je názov programu v hlavnej operačnej pamäti počítača, nadradený CPU a prepísanie kľúčových funkcií robota s doplnkom.
V skutočnosti tá časť vášho programu, ktorá funguje na CPU, je hostiteľ, a vaša grafická karta - príloha. Logicky môžete použiť ako sadu multiprocesorov (malé 4) plus ovládač CUDA.

Ryža. 4. Príloha
Povedzme, že na našom rozšírení chceme spustiť procedúru v N vláknach (preto chceme robota paralelizovať). Pokiaľ ide o dokumentáciu CUDA, nazvime túto procedúru jadro.
Zvláštnosťou architektúry CUDA je organizácia blokového sita, ktorá nie je obmedzená bohatými prísadami toku (obr. 5). Ovládač CUDA nezávisle distribuuje zdroje a zostavuje medzi vláknami.

Ryža. 5. Organizácia tokov
Na obr. 5. jadro je označené ako Kernel. Všetky vlákna, ktoré zasiahnu jadro, sú spojené do blokov (Block) a bloky sú svojou povahou spojené do mriežky (Grid).
Ako je možné vidieť na obrázku 5, na identifikáciu tokov sa používajú dvojsvetové indexy. CUDA rozrobniky dali možnosť pracovať s trivum, dvojsvetovými alebo jednoduchými (jednosvetovými) indexmi, navyše, keďže je to pre programátora jednoduchšie.
V divokom type je index triviálny pre vektory. Pre dermálny závit bude uvedené nasledovné: index vlákna v strede bloku threadIdx a index bloku v strede mriežky blockIdx. Pri spustení budú všetky vlákna obnovené bez ďalších indexov. V skutočnosti programátor prostredníctvom indexu qi riadi ovládanie, čo znamená, že jeho časť je spracovaná v pote pokožky.
Dôkazy o zásobovaní, prečo si predajcovia sami odobrali takúto organizáciu, nie sú triviálne. Zdá sa, že jedným z dôvodov je, že jeden blok zaručene vyhrá na jeden Pridám multiprocesor, ale jeden multiprocesor môže vyhrať šprot rôznych blokov. Ďalšie dôvody na objasnenie boli uvedené v hodine článku.
Blok úloh (tokov) je na multiprocesore porazený časťami alebo skupinami nazývanými warp. Rozšírenie warpu pre aktuálny moment vo grafických kartách z podpory CUDA je až 32 streamov. Príkazy v strede warp poolu sú nastavené na štýly SIMD, tj. všetky vlákna v strede osnovy môžu mať naraz iba jednu inštrukciu.
Tu je ďalšie varovanie. V architektúrach, ktoré sú momentálne v čase písania tohto článku, je počet procesorov v strede jedného multiprocesora 8, nie 32. Je jasné, že nie všetky warpy sa premenia za hodinu, sú rozdelené na 4 časti, sú porazené postupne (pretože procesy) .
Ale po prvé, predajcovia CUDA neregulujú veľkosť osnovy. Vo svojich robotoch smrad nastavuje parameter velkost osnovy a nie cislo 32. Inym sposobom je z logickeho hladiska vlastna osnova minimalne pool flows, o ktorom sa da povedat, ze vsetky toky v uprostred cyklu sa počítajú naraz - a s každým dňom, umožňujú vyriešiť systém nebude narušený.
3.1.1. Odsoľovanie
No, obviňujete jedlo: ak práve v tej chvíli všetky prúdy v strede osnovy píšu práve túto inštrukciu, ako sa potom môžete zbaviť? Aj keď sa kód programu vymaže, pokyny sa budú líšiť. Tu vstupuje do hry štandardné programovacie riešenie SIMD (obrázok 6).

Ryža. 6. Organizácia ladenia v SIMD
Poď ďalší kód:
ak (podmienka)B;
V prípade SISD (Single Instruction Single Data) je operátor A viconuovaný, je znovu overený mysľou, potom sú operátori B a D odmietnuté (takže myseľ je pravdivá).
Majme teraz 10 streamov, ktoré sú napísané v štýle SIMD. Vo všetkých 10 streamoch zlyháme operátor A, potom skontrolujeme mentálny stav a zdá sa, že v 9 z 10 streamov je to pravda a v jednom je to zlé.
Uvedomil som si, že nemôžeme spustiť 9 vlákien na vykonanie operátora B a jedno na vykonanie operátora C, takže všetky vlákna môžu naraz spustiť iba jednu inštrukciu. K tejto vapadke treba dodat takto: hrniec sa "zapicha" na zátylku, aby sa vyčistilo, aby víno nedávalo hold a zobralo sa 9 prúdov, ktoré zostali. von. Poďme „nabehnúť“ 9 tokov, ktoré prekonali operátor B, a prejsť jeden tok s operátorom C. Ďalšie vlákna sa opäť spoja a naraz porazia operátor D.
Je tu zhrnutý výsledok: nielenže sú zdroje procesorov vyčerpané na prázdne prebrúsenie bitiek v prúdoch, ktoré sa odtrhli, oveľa bohatšie, že budeme v rozpakoch v dôsledku porážky OBIGI gіlki.
Nie všetko je však také zlé, ako vidíte na prvý pohľad. Veľkou výhodou techniky je vidieť tie, ktoré sa zameriavajú na dynamickú jazdu CUDA ovládača a pre programátora je smrad jasný. Zároveň, keď beháte s príkazmi SSE z moderných CPU (stačí vyskúšať 4 kópie algoritmu naraz), programátor je zodpovedný za detaily: kombinujte údaje po štyroch, nezabudnite na skríning a začnite písať na nízka úroveň, v skutočnosti, ako v assembleri.
Z fúzov vyššie spomínaného ufňukaného ešte jeden úctyhodný visnovok. Razgaluzhennya je dôvodom poklesu produktivity mocných síl. Shkidlivimi є menej ako tі razgaluzhennya, na ktorej sa prúdy rozchádzajú uprostred jedného bazéna osnovných prúdov. V niektorých prípadoch sa toky rozšírili v strede jedného bloku, ale v rôznych warp bazénoch alebo v strede rôznych blokov, bez toho, aby to spôsobilo akýkoľvek efekt.
3.1.2. Interakcia medzi prúdmi
V čase písania tohto článku, či interakcia medzi vláknami (synchronizácia a výmena údajov) bola možná len v strede bloku. To je dôvod, prečo je nemožné organizovať sa navzájom medzi prúdmi rôznych blokov, pretože sú korozívne s menšími dokumentačnými schopnosťami.
Aká je cena nezdokumentované funkcie oni koristuvatisya vkrai sa neodporúča. Dôvodom je, že zápach je založený na špecifických hardvérových vlastnostiach druhého systému.
Synchronizácia všetkých úloh v strede bloku je riadená volaním funkcie __synchtreads. Výmena peňazí je možná prostredníctvom pamäte, ktorá je rozdelená, takže je tak dôležitá pre všetky úlohy v strede bloku.
3.2. Pamäť
CUDA má šesť typov pamäte (obr. 7). Ce register, lokálna, globálna, distribuovaná, konštantná a textúrová pamäť.
Taký veľký počet je ovplyvnený špecifikami grafickej karty a prvými uznaniami, ako aj tým, že predajcovia zostavujú systém yakomoga lacnejšie a obetujú rôzne spôsoby, či už univerzálne alebo švédske.

Ryža. 7. Pozrite si pamäť CUDA
3.2.0. Registratúra
Pokiaľ je to možné, kompilátor sa snaží umiestniť všetky lokálne zmenené funkcie do registrov. Prístup k takýmto zmenám je obmedzený maximálna rýchlosť. Streamovacia architektúra má k dispozícii 8192 32-bitových registrov na jeden multiprocesor. Ak chcete určiť, koľko registrov je dostupných pre jedno vlákno, musíte rozdeliť číslo (8192) na veľkosť bloku (počet vlákien pre nové vlákno).
Pri značnom počte 64 tokov na blok je celkovo 128 registrov (treba mať objektívne kritériá, ale 64 by malo byť v strede pre bohaté pracovné miesta). Naozaj, 128 registrov nvcc nie je vôbec vidieť. Volajte na VIN, nedávajte viac ako 40, ale riešte zmenu lokálna pamäť. Zdá sa teda, že na jednom multiprocesore sa dá vyhrať kopa blokov. Kompilátor sa pokúsi maximalizovať počet blokov, ktoré je možné spracovať naraz. Pre väčšiu efektivitu je potrebné vziať menej ako 32 registrov. Potom môžete teoreticky spustiť 4 bloky (8 warp-іv, takže 64 vlákien v jednom bloku) na jednom multiprocesore. Tu je však potrebné viac chrániť zdieľanú pamäť, ktorá je zaneprázdnená vláknami, takže ak jeden blok zaberie všetku pamäť, ktorá sa zdieľa, dva takéto bloky nemôžu byť obsadené multiprocesorom súčasne.
3.2.1. Lokálna pamäť
V prípade, že lokálne dáta procedúr zaberajú príliš veľa miesta, alebo ich kompilátor nevie vypočítať naposledy, môžete ich umiestniť do lokálnej pamäte. Komu môžete akceptovať napríklad dané ukazovatele typov rôznych typov rozšírení.
Fyzicky je lokálna pamäť analógom globálnej pamäte a pracuje s tієyu a swidkіst. V čase písania článku neboli známe žiadne mechanizmy, ktoré by umožňovali explicitne získať kompilátor pomocou lokálnej pamäte pre konkrétne zmeny. Je dôležité skontrolovať lokálnu pamäť a nie vikoristovuvat її zovsіm (oddiel 4 „Odporúčania na optimalizáciu“).
3.2.2. globálna pamäť
Dokumentácia CUDA je jedným z hlavných úspechovTechnológia na vyvolanie možnosti dostatočného adresovania globálnej pamäte. Takže môžete čítať z ľubovoľného stredu pamäte a môžete písať rovnakým spôsobom v určitom strede (na GPU to tak neznie).
Zamerajte sa na univerzálnosť na tento konkrétny typ byť privedený k plaču shvidkistyu. Globálna pamäť sa neukladá do vyrovnávacej pamäte. Vaughn pratsyuє ešte viac povіlno, kіlkіst zvernenі do globálnej pamäte sіd kedykoľvek minimizuvati.
Globálna pamäť je nevyhnutná na uloženie výsledkov robotických programov pred ich úpravou na hostiteľovi (v predvolenej pamäti DRAM). Dôvodom je, že pamäť je globálna – jediný druh pamäte, ktorý možno zaznamenať.
Zmeny vyjadrené kvalifikátorom __global__, uložené v pamäti sveta. Globálnu pamäť je možné prezerať aj dynamicky volaním funkcie cudaMalloc(void* mem, int size) na hostiteľovi. Túto funkciu pridám, nie je možné ju zavolať. Znie to tak, že hostiteľský program sa dokáže postarať o pamäť, čo funguje na CPU. Údaje z hostiteľa môžete prepísať kliknutím na funkciu cudaMemcpy:
cudaMemcpy(void* gpu_mem, void* cpu_mem, veľkosť int, cudaMemcpyHostToDevice);
Takže môžete začať opačný postup sami:
cudaMemcpy(void* cpu_mem, void* gpu_mem, veľkosť int, cudaMemcpyDeviceToHost);
Táto wiki funguje aj od hostiteľa.
Pri práci s globálnou pamäťou je dôležité pamätať na pravidlá spájania. Hlavnou myšlienkou je, že tretia časť pamäte je uložená až do poslednej strednej pamäte, navyše 4,8 alebo 16 bajtov. S tým je prvé vlákno vinné z prepínania adresy, vibrovania na kordóne, samozrejme 4,8 alebo 16 bajtov. Adresy, ktoré cudaMalloc otáča, sú aspoň 256 bajtov za hranicou.
3.2.3. Pamätajte, čo sa delí
Pamäť, ktorá sa delí, nie je možné uložiť do vyrovnávacej pamäte, ale pamäť je rýchla. Її sa odporúča vicorate ako kontrola vyrovnávacej pamäte. Na jeden multiprocesor je k dispozícii celkovo 16 KB zdieľanej pamäte. Vydelením čísla počtom dní v bloku vezmeme maximálne množstvo pamäte, ktorá je rozdelená, dostupná pre jeden stream (keďže sa plánuje vyhrať nezávisle od všetkých streamov).
Pamätajte na ryžu, ktorá je rozdelená, tie, ktoré sú adresované rovnako pre všetkých vodcov stredného bloku (obr. 7). Je zrejmé, že môžete vyhrať iba jeden blok na výmenu dát medzi streammi.
Je zaručené, že na hodinu sa blok na multiprocesore uloží do pamäte. Keďže sa však blok zmení na multiprocesore, nie je zaručené, že sa namiesto neho uloží starý blok. Preto nestačí snažiť sa synchronizovať úlohy medzi blokmi, nechať ich v pamäti ako dáta a spoliehať sa na ich úspory.
Zmeny vyjadrené kvalifikátorom __shared__ sa uložia do pamäte, v ktorej sa zdieľajú.
shared_float mem_shared;
Nabudúce sa ubezpečte, aká je pamäť, čo sa delí, len pre blok. Na tento účel je potrebné hackovať rovnako ako vyrovnávaciu pamäť po vyhľadaní rôznych prvkov poľa, napríklad:
float x = mem_shared;
De threadIdx.x – index x vlákna v strede bloku.
3.2.4. Neustála pamäť
Konštantná pamäť sa ukladá do vyrovnávacej pamäte, ako je vidieť na obr. 4. Cache sa používa v jedinej inštancii jedného multiprocesora, čo je aj hlavnou úlohou stredného bloku. Na hostiteľovi môžete zapisovať do konštantnej pamäte volaním funkcie cudaMemcpyToSymbol. Pridám stálu pamäť, ktorá je dostupná len na čítanie.
Konštantná pamäť je pre vikoristan výhodnejšia. Môžete rozmіschuvati in niy danі be-aký typ toho čítať їх za pomoc jednoduchej príťažlivosti.
#definujte N 100
Constant__int gpu_buffer[N];
void host_function()
int cpu_buffer[N];
cudaMemcpyToSymbol(gpu_buffer, cpu_buffer, sizeof(int )*N);
// __global__ znamená, že zariadenie_kernel je jadro, takže ho možno spustiť na GPU
Global__void device_kernel()
int a = gpu_buffer;
int b = gpu_buffer + gpu_buffer;
// gpu_buffer = a; PÁRTY! konštantná pamäť je k dispozícii iba na čítanie
Keďže vyrovnávacia pamäť sa používa na stálu pamäť, prístup k nej je bezpečný. Jediné, ale stále veľké, malé množstvo konštantnej pamäte je v tom, že je menšia ako 64 kB (pre celú prílohu). Prečo je zrejmé, že v kontextovej pamäti je možné uložiť len malé množstvo dát, ktoré sú často víťazné.
3.2.5. Pamäť textúry
Pamäť textúr sa ukladá do vyrovnávacej pamäte (obr. 4). Pre skin multiprocesor je len jedna cache, takže celá cache je najväčšia pre celý stredný blok.
Názov textúrnej pamäte (a, žiaľ, funkcionality) je znížený, aby chápal „textúra“ a „textúra“. Textúrovanie - proces nanášania textúr (len obrázkov) na polygón počas procesu rastrovania. Pamäť textúr je optimalizovaná pre 2D dáta a môže byť možné:
shvidka vibirka hodnota pevného rozmіru (bajt, slovo, subwiyne alebo štvorslovo) z jedno- alebo dvojsvetového poľa;
- Špecifiká funkcií, ako ukazujú, ako a znaky funkcií sa berú.
- Špecifiká zmeny, pretože slúžia na určenie typu pamäte GPU.
- Špecifiká spúšťania jadra GPU.
- Zavedené zmeny pre identifikáciu vlákien, blokov a ďalších parametrov pri písaní kódu v jadre GPU.
- Dodatkovі typy zmien.
- __hostiteľ__- Zavolajte na CPU, zavolajte na CPU (v princípe môžete a nie špecifikovať).
- __globálny__- Volané na GPU, volané na CPU.
- __zariadenie__- Volané na GPU, volané z GPU.
- veľkosť mriežky- Otvorenie blokovej mriežky (dim3), videné pri rolovaní,
- blockSize- Blok Rozmіr (dim3), videný pre rozrahunkіv,
- sharedMemSize- Rozšírenie prídavnej pamäte, ktoré sa prejaví pri spustení jadra,
- cudaStream- Zmena cudaStream_t, ktorá nastavuje prúd, v ktorom sa vytvorí knôt.
- gridDim- Rozšírenie mriežky, môže byť typu dim3. Umožňuje rozpoznať svet mriežky, videný pre cyklus streamovania jadra.
- blockDim- Otvorenosť k bloku, takže typ dim3 môže sám. Umožňuje rozpoznanie bloku, ktorý bol videný za hodinu prietokového cyklu jadra.
- blockIdx- Index závitového bloku v čísle na GPU môže byť typu uint3.
- threadIdx- Index vlákna vlákna počítaný na GPU môže byť typu uint3.
- warpSize- Rozmіr warp, maє typ int (zatiaľ som neskúšal vicorist).
- správa zariadení– povoliť funkcie pre všeobecnú správu GPU (odstrániť informácie o kapacite GPU, prepínať medzi GPU na hodinu v režime SLI).
- Správa vlákien- Správa vlákien.
- riadenie toku- Manažment toku.
- manažment udalostí- funkcia vytvárania a riadenia udalostí.
- Kontrola vykonávania– funkcie na spustenie týchto vikoník jadra CUDA.
- Správa pamäte– Funkcie obnovy pamäte GPU.
- Správca referencií textúr– práca s objektmi textúr cez CUDA.
- Interoperabilita OpenGL– funkcie interagujúce s OpenGL API.
- Interoperabilita Direct3D 9– Funkcie interagujúce s Direct3D 9 API.
- Interoperabilita Direct3D 10– Funkcie interagujúce s Direct3D 10 API.
- Spracovanie chýb- Funkcie na spracovanie milostí.
- Odobrať dáta pre rozrakhunkiv.
- Skopírujte údaje do pamäte GPU.
- Výpočet Vikonati v GPU prostredníctvom funkcie jadra.
- Skopírujte vypočítané údaje z pamäte GPU do RAM.
- Obdivujte výsledky.
- Vivіlniti vikoristovuvanі zdroje.
- devPtr- Vkazivnik, v ktorom sú zaznamenané adresy videnej pamäte,
- počítať- Rozšírte pamäť, ktorá sa zobrazuje v bajtoch.
- cudaSuccess- s úspešnou víziou pamäti
- cudaErrorMemoryAllocation- pomocou videnia pamäti
- dst- vkazivnik, čo pomstiť adresu miesta uznania kópie,
- src- Vkazivnik, čo pomstiť adresu kópie dzherel,
- počítať- rozmer kopírovaného zdroja v bajtoch,
- cudaMemcpyKind– preklad, ktorý označuje priamu kópiu (môže byť cudaMemcpyHostToDevice, cudaMemcpyDeviceToHost, cudaMemcpyHostToHost, cudaMemcpyDeviceToDevice).
- cudaSuccess - so vzdialeným kopírovaním
- cudaErrorInvalidValue – neplatné parametre pre argument (napríklad záporná veľkosť kópie)
- cudaErrorInvalidDevicePointer - indikátor neplatnej pamäte pre grafickú kartu
- cudaErrorInvalidMemcpyDirection - nesprávny smer
- *udalosť– indikátor pre záznam spracovania udalosti.
- cudaSuccess - v čase úspechu
- cudaErrorMemoryAllocation - pamäť pardon
- udalosť– popisovač udalosti, čo sa deje,
- Prúd- Číslo streamu, v ktorom je zaznamenaný (náš pohľad má hlavný nulový stream).
- cudaSuccess - v čase úspechu
- cudaErrorInvalidValue - neplatná hodnota
- cudaErrorInitializationError - inicializácia pardon
- cudaErrorPriorLaunchFailure - pardon za asynchrónny štart funkcie
- udalosť- rukoväť udalosti, ktorej prechod je uvoľnený.
- cudaSuccess - v čase úspechu
- cudaErrorInitializationError - inicializácia pardon
- cudaErrorPriorLaunchFailure - pardon za asynchrónny štart funkcie
- cudaErrorInvalidValue - neplatná hodnota
- cudaErrorInvalidResourceHandle - neplatný popisovač udalosti
- Procesor: Pentium Dual-Core E5200 2,5 GHz;
- Základná doska: Gigabyte P35-S3;
- Pamäť: 2x1GB GoodRam PC6400 (5-5-5-18-2T)
- Grafická karta: MSI NX8800GT-T2D256E-OC;
- Pevný disk: 320 GB WD3200AAKS;
- Živá jednotka: CoolerMaster eXtreme Power 500-PCAP;
- Operačný systém: Windows XP SP2;
- TMPGEnc 4.0 XPress 4.6.3.268;
- Ovládače grafickej karty: ForceWare 180.60.
normalizované adresovanie plávajúcimi číslami v intervaloch. Potim їх je možné zvoliť, vikoristuuuu normalіzovanu adresovanie. Výsledná hodnota bude slovo typu float4 s intervalom ;
CudaMalloc((void**) &gpu_memory, N*sizeof (uint4 )); // zrejme pamäť GPU
// Úprava parametrov stromu textúr
Texture.addressMode = cudaAddressModeWrap; // režim Zabaliť
Texture.addressMode = cudaAddressModeWrap;
Texture.filterMode = cudaFilterModePoint; //najbližšia hodnota
texture.normalized = false; // nekrúti normalizované adresovanie
CudaBindTexture(0, textúra, gpu_memory, N ) // zmeňme pamäť na textúru
cudaMemcpy(gpu_memory, cpu_buffer, N*sizeof(uint 4), cudaMemcpyHostToDevice ); // skopírujte údaje doGPU
// __global__ znamená, že zariadenie_kernel je jadro, takže ho treba paralelizovať
Global__void device_kernel()
uint4 a = tex1Dfetch(textura,0); // týmto spôsobom si môžete vybrať viac údajov!
uint4 b = tex1Dfetch(textura,1);
int c = a.x*b.y;
...
3.3. Jednoduchý zadok
Ako jednoduchý zadok sa odporúča pozrieť sa na program cppIntegration z CUDA SDK. Vaughn demonštruje pracovný postup CUDA, ako aj nvcc (špeciálny kompilátor C++ pre Nvidiu) verziu MS Visual Studio, ktorá zjednoduší vývoj programov na CUDA.
4.1. Správne vykonajte porážku svojho šéfa
Nie všetky úlohy sú vhodné pre architektúru SIMD. Napríklad vaša úloha pre koho nie je pripojená, je možné, nie je možné použiť GPU. A napriek tomu ste tvrdo porušili triky GPU, bolo potrebné rozdeliť algoritmus na také časti, aby smrad mohol efektívne poraziť štýl SIMD. Je potrebné - zmeniť algoritmus na zlepšenie vašej úlohy, vymyslieť nový - ten, ktorý by bol dobrý pre SIMD. Ako príklad inej oblasti GPU môžete implementovať pyramídové skladanie prvkov v poli.
4.2. Vyberte typ pamäte
Umiestnite svoje údaje do textúrovej alebo konštantnej pamäte, aby sa všetky úlohy jedného bloku previedli do jedného pamäťového slotu alebo do blízkosti naskladaných slotov. Tieto dva údaje možno efektívne spracovať pomocou dodatočných funkcií text2Dfetch a text2D. Pamäť textúr je špeciálne optimalizovaná pre dva svety.
Dobite globálnu pamäť z pamäte, ktorá je rozdelená, pretože všetky úlohy sú nesystematicky rozdelené do rôznych, ďalekosiahlych, jedného druhu pamäťových miest (s rôznymi adresami alebo súradnicami, ako sú 2D / 3D dáta).
globálna pamäť => pamäť, ktorá je rozdelená
syncthreads();
Zbierajte údaje v pamäti
syncthreads();
globálna pamäť<= разделяемая память
4.3. Pripomeňte lichnikom pamäť
Príznak kompilátora --ptxas-options=-v vám umožňuje presne povedať, ktoré slová a akú pamäť (registre, ktoré sú distribuované, lokálne, konštantné) vo victorist. Keďže kompilátor používa lokálnu pamäť, viete o tom svoje. Analýza údajov o počte a typoch pamätí, ktoré sú víťazné, vám môže výrazne pomôcť pri optimalizácii programu.
4.4. Pokúste sa minimalizovať počet zdieľaných registrov a spomienok
Čím väčšie je jadro warp registra alebo pamäť, ktorá je rozdelená, tým menej tokov (primárny warp-iv) môže súčasne vyhrať na multiprocesore, pretože zdroje multiprocesora sa vymieňajú. Preto malé zvýšenie obsadenosti registrov a pamätí, ktoré sa rozširujú, môže v niektorých prípadoch viesť k dvojnásobnému zníženiu produktivity – dokonca aj prostredníctvom tých, ktoré sú teraz dvakrát menšie ako warp-in pri raz na multiprocesore.
4.5. Spomienka na to, čo sa delí, miestny poslanec.
Ako keby kompilátor Nvidia spôsobuje únik dát v lokálnej pamäti 'yat, scho razdelyaetsya (zdieľaná pamäť).
Väčšinu času je možné kompilátor zmeniť v lokálnej pamäti, pretože sa nevyberá príliš často. Napríklad batéria je devi akumulujúce hodnoty, rozrakhovuyuschos s tsiklі. Rovnako ako veľký cyklus pre obsyagi kód (aj keď nie na hodinu vykonanú!), Kompilátor môže umiestniť vašu batériu do lokálnej pamäte, tk. Vіn vykoristovuєtsya veľmi zriedka, a registre sú málo. Náklady na produktivitu môžu byť niekedy značné.
No, ak to naozaj málokedy víťaz zmeníte - radšej si to umiestnite do globálnej pamäte.
Ak chcete, aby kompilátor automaticky alokoval takéto zmeny v lokálnej pamäti, môže to byť rozumné, ale nie v skutočnosti. Vyznať sa na určitom mieste s pripravovanými úpravami programov nie je jednoduché, keďže sa často častejšie mení. Kompilátor môže alebo nemusí preniesť takúto zmenu do pamäte registra. Ak bude modifikátor __global__ špecifikovaný explicitne, programátor si to uvedomí brutálnejšie.
4.6. Regulačné cykly
Rotačné cykly sú štandardnou metódou na zvýšenie produktivity v bohatých systémoch. Podstata yogo je v tom, že na skin iterácii môžete vyhrávať stále viac a viac, meniť počet iterácií takým spôsobom, a to znamená počet mentálnych prechodov, aby mohol vyhrať procesor.
Os je spôsob, akým je možné otvoriť cyklus významu poľa sumi (napríklad celé):
int a[N]; intsum;
pre (int i=0;i Zrozumilo, cykly je možné spustiť aj ručne (ako je uvedené vyššie), ale prax je neproduktívna. Je lepšie upraviť šablóny C++ pre viac funkcií, ktoré potrebujete vedieť. šablóna trieda ArraySumm Device__ static T exec (const T * arr) ( return arr + ArraySumm šablóna trieda ArraySumm<0,T> Device__ static T exec(const T* arr) ( return 0; ) pre (int i=0;i summ+= ArraySumm<4,int>::exec(a); Označte jednu značku ako vlastnosť kompilátora nvcc. Kompilátor by mal vždy umožňovať zatvorenie funkcií typu __device__ (pre istotu použite špeciálnu direktívu __noinline__) . Otzhe, môžete sa inšpirovať skutočnosťou, že pažba, podobne ako špicatá, sa hnevá na jednoduchú sekvenciu operátorov a prečo nekonať pre efektivitu kódu napísaného rukou. Avšak pre divoký typ (nie nvcc) nie je možné, aby mal niekto korisť, pretože inline nie je viac ako vstup kompilátora a môžete ho ignorovať. Preto nie je zaručené, že vaše funkcie budú fungovať. Prehľadávajte dátové štruktúry podľa 16-bajtového kordónu. V tomto prípade môže kompilátor získať špeciálne inštrukcie pre nich, takže môžu získať množstvo dát raz za 16 bajtov. Ak je štruktúra úveru 8 b a menej, môžete ju zmeniť o 8 b. Prípadne môžete vybrať dve 8-bajtové zmeny naraz, skombinovať dve 8-bajtové zmeny do štruktúry za dodatočným spojením alebo ich vypísať. S nasledujúcim by sa malo zaobchádzať opatrne, kompilátor môže ukladať údaje do lokálnej pamäte, ale nie do registra. Pamäť, ktorá sa distribuuje, je organizovaná v 16 (spolu!) bankách pamäte so 4-bajtovým krokomerom. Na hodinu sa zásoba warp vlákien na multiprocesore rozdelí na dve polovice (ako veľkosť warpu = 32) po 16 vláknach, čo umožňuje prístup do pamäte pomocou karty. Úlohy v rôznych poloviciach osnovy nie sú v rozpore so spomienkami, ktoré sú rozdelené. Prostredníctvom zavdannya sa jedna polovica warp poolu zredukuje na rovnaké banky pamäte, z čoho obviňuje kolaps a v dôsledku toho pokles produktivity. Zavdannya v hraniciach jednej polovice osnovy môže vyrásť do rôznych dedín pamäti, ktoré sú rozdelené, s piesňou Croc. Optimálna veľkosť je 4, 12, 28, ..., 2 n-4 bajtov (obr. 8). Ryža. 8. Optimálne prispôsobenie.
Chi nie je optimálna veľkosť - 1, 8, 16, 32, ..., 2^n bajtov (obr. 9). Ryža. 9. Suboptimálne prispôsobenie
Pokúste sa preniesť medzivýsledky na hostiteľa na spracovanie pre ďalší procesor. Ak neimplementujete celý algoritmus, vezmite časť hlavnej časti na GPU a ponechajte CPU menej úloh. Autor tohto článku napísal knižnicu MGML_MATH, ktorú je možné preniesť pre prácu s jednoduchými priestrannými objektmi ako praktický kód na rozšírenie aj na hostiteľa. Knižnica MGML_MATH môže byť použitá ako rámec pre písanie CPU/GPU prenosných (alebo hybridných) systémov pre vývoj fyzických, grafických a iných vesmírnych úloh. Hlavnou výhodou je, že jeden a ten istý kód je možné vyladiť na CPU aj na GPU a ak je prezentovaný v knižnici, je možné ho nainštalovať na druhú stranu. Chris Kaspersky. Technika optimalizácie programu. Efektívna obnova pamäte. - Petrohrad: BHV-Petersburg, 2003. - 464 s.: il. CUDA Programming Guide 1.1 ( http://developer.download.nvidia.com/compute/cuda/1_1/NVIDIA_CUDA_Programming_Guide_1.1.pdf )
Programovacia príručka CUDA 1.1. strana 14-15 Programovacia príručka CUDA 1.1. strana 48 Poviem vám o kľúčových bodoch kompilátora CUDA, rozhraní CUDA runtime API, dobre, porozprávajme sa o tom, použijem CUDA hack na nekoherentné matematické výpočty. Začnime. S rôznymi GPU môžete nastaviť mriežku potrebného rozšírenia a upraviť bloky podľa potrieb vašej úlohy. MyKernelFunc<< Takže varto hádajte o prebudení zmien: Na ďalšie typy zmien a ich špecifiká sa pozrieme v zadkoch robotov spamäti. Runtime API CUDA obsahuje nasledujúce skupiny funkcií: manažér. Je potrebné vypočítať súčet dvoch vektorov v počte N prvkov. Dostali sme maximálnu veľkosť nášho bloku: 512 * 512 * 64 vlákien. Keďže máme jednorozmerný vektor, tak zatiaľ budeme môcť miešať víťazstvá x-káblovania nášho bloku, takže potrebujeme len jeden roj vlákien na blok (obr. 3). S úctou, x je veľkosť bloku 512, takže môžeme pridávať vektory naraz, počet takýchto N<= 512 элементов. В прочем, при более массивных вычислениях, можно использовать большее число блоков и многомерные массивы. Так же я заметил одну интересную особенность, возможно, некоторые из вас подумали, что в одном блоке можно задействовать 512*512*64 = 16777216 нитей, естественно это не так, в целом, это произведение не может превышать 512 (по крайней мере, на моей видеокарте). Samotný program vyžaduje nasledujúce kroky: Vopred napíšme funkciu jadra, aby sme mohli zložiť vektory: //Predbežný výsledok. V tomto poradí sa paralelizácia automaticky vypne pri spustení jadra. Táto funkcia tiež musí zmeniť threadIdx a pole x, čo umožňuje nastaviť konzistenciu medzi elementom vector a vláknom v bloku. Robimo rozrahunok prvku kože vektora okremoї vlákna. Napíšeme kód, ktorý je platný pre 1 a 2 body v programe: //Inicializácia vektorových hodnôt //Ukazovatele hádanky o grafickej karte //Zobrazenie pamäte pre vektory na grafickej karte //Skopírujte údaje pre hádanku o grafickej karte Ak chcete zobraziť pamäť na grafickej karte, funkcia cudaMalloc, ako môže ďalší prototyp: * Zdrojový kód Tsei bol zvýraznený pomocou Zvýrazňovača zdrojového kódu. Kód podľa wiki jadra: // popisovač udalosti "a CudaEventCreate(&syncEvent); //Vytvoriť udalosť // Až teraz môžeme zobrať výsledok rozrahunky Udalosť je vytvorená pre ďalšiu funkciu cudaEventCreate, prototyp je možné vidieť: Na malej 4 je blok „Kontrola prechodu udalosti“ volaním funkcie cudaEventSynchronize. Nakoniec zobrazíme výsledok na obrazovke a čisté zdroje. //
CudaEventDestroy(syncEvent); CudaFree(devVec1); Odstrániť vec1; vec1 = 0; PS: Wijslo nie je príliš krátke. Aj spodіvayus, scho nie je unavený. Ak potrebujete všetok externý kód, môžem vám ho poslať poštou. Štítky: Pridajte štítky Vo vývoji moderných procesorov je trend k postupnému zvyšovaniu počtu jadier, čím sa zvyšuje možnosť paralelných výpočtov. Už dávno je tu GPU, ktoré rovnakým spôsobom výrazne pretláča centrálny procesor. Prvý počet možností grafických procesorov už zohľadnili aj iné spoločnosti. Po prvé, skúste vicoristovuvati grafické priskoryuvachі pre nevojenské výpočty boules z konca 90. rokov. O niečo neskôr sa vzhľad shaderov stal odrazovým mostíkom k vývoju úplne novej technológie a v roku 2003 bol pochopený GPGPU (General-purpose graphics processing units). Dôležitú úlohu zohráva vývoj iniciatívy BrookGPU, ktorá je špeciálnym rozšírením filmu C. Pred príchodom BrookGPU mohli programy pracovať s GPU iba cez Direct3D API alebo OpenGL. Brook umožnil maloobchodníkom pracovať s primárnym médiom a samotný kompilátor za pomoci špeciálnych knižníc implementoval interoperabilitu s GPU na nízkej úrovni. Takýto pokrok okamžite nezískal rešpekt lídrov tohto odvetvia - AMD a NVIDIA, pretože sa zaoberali vývojom vlastných softvérových platforiem pre negrafické výpočty na grafických kartách. Nikto lepšie ako predajcovia GPU nepozná všetky nuansy a vlastnosti svojich produktov, čo umožňuje spoločnostiam čo najefektívnejšie optimalizovať softvérový komplex pre konkrétne hardvérové riešenia. NVIDIA zároveň vyvíja platformu CUDA (Compute Unified Device Architecture), AMD má podobnú technológiu s názvom CTM (Close To Metal) alebo AMD Stream Computing. Môžeme sa pozrieť na realizovateľnosť CUDA a v praxi odhadnúť realizovateľnosť grafického čipu G92 grafickej karty GeForce 8800 GT. A pozrime sa dopredu na nuansy vizionárskeho rozrakhunkiva za pomoci grafických procesorov. Ich hlavná výhoda spočíva v tom, že grafický čip je navrhnutý na báze viacerých vlákien a skin core super CPU je navrhnutý na základe následných inštrukcií. Či je moderný GPU multiprocesor, ktorý sa skladá z veľkého počtu počítacích klastrov, s nedostatkom ALU v koži. Najsofistikovanejší súčasný čip GT200 sa skladá z 10 takýchto klastrov s 24 tokmi procesorov na skin. Testovaná grafická karta GeForce 8800 GT založená na čipe G92 má po 16 stream procesorov. CPU obaľuje SIMD SSE bloky pre vektorové výpočty (jedna inštrukcia viac dát - jedna inštrukcia cez numerické dáta), čo vyžaduje transformáciu dát zo 4 vektorov. GPU spracováva streamy skalárne, tzn. jedna inštrukcia zastosuetsya cez množstvo vlákien (SIMT - jedna inštrukcia s viacerými vláknami). Tse umožňuje transformáciu údajov vo vektoroch a umožňuje dostatočné oddelenie v prúdoch. Blok výpočtu kože môže mať priamy prístup do pamäte. Touto šírkou pásma je kapacita video pamäte, počet rôznych pamäťových radičov (najvyššia G200 má 8 kanálov pri 64-bitovej verzii) a vysoké prevádzkové frekvencie. Vo všeobecnosti sa pri najnáročnejších úlohách pri práci s veľkým nasadením tieto GPU zdajú byť bohatšie ako CPU. Nižšie môžete vidieť ilustráciu tohto tvrdenia:
O veľkom potenciáli grafických procesorov však nešlo, keďže vyhrať sa dá a vyžaduje si to špecifický prístup k vývoju softvérových produktov. Všetko je implementované v hardvérovom a softvérovom prostredí CUDA, keďže je zložené z množstva softvérových vrstiev – vysokoúrovňového CUDA Runtime API a nízkoúrovňového CUDA Driver API. V prípade praktickej implementácie CUDA potom posledná hodina technológie bola víťazná už len pre vyššie špecializované matematické výpočty v oblasti fyziky elementárnych častíc, astrofyziky, medicíny, či predpovedania zmien na finančnom trhu. Navyše sa technológia krok za krokom približuje až k obyčajným jadrám a do Photoshopu existujú špeciálne zásuvné moduly, ktoré dokážu vypočítať prítlak GPU. Na špeciálnej stránke si môžete stiahnuť celý zoznam programov, ktoré označujú NVIDIA CUDA. Ako praktický test novej technológie na grafickej karte MSI NX8800GT-T2D256E-OC ju zrýchlime pomocou programu TMPGEnc. Tento produkt je komerčný (nová verzia stojí 100 USD), ale ku grafickým kartám MSI sa dodáva ako bonus k skúšobnej verzii na 30 dní. Verziu si môžete stiahnuť zo stránky predajcu, no na inštaláciu TMPGEnc 4.0 XPress MSI Special Edition potrebujete originálny disk s ovládačmi z MSI karty – bez nového programu sa nainštalovať nedá. Ak chcete zobraziť najúplnejšie informácie o možnostiach enumerácie v CUDA a podobne ako v iných video adaptéroch, môžete použiť špeciálny nástroj CUDA-Z. Tu je niekoľko informácií o našej grafickej karte GeForce 8800GT: Porovnávame rýchlosť konverzie jedného a toho istého HD-videa pri expanzii len pre ďalšie CPU a dodatočnú aktiváciu CUDA v programe TMPGEnc na ďalšej konfigurácii: Pre čiastkové vaky testov sa vzali tieto údaje: Program TMPGEnc má v tejto testovacej konfigurácii indikátor obsadenia CPU a CUDA, ktorý ukazuje vyťaženie CPU približne na 20 % a grafického jadra na 80 %. Máme 100% výsledok, ale pri konverzii bez CUDA a rôznych v priebehu hodiny to tak môže, ale nemusí byť (aj keď je to stále є). Malé množstvo pamäte 256 MB tiež nie je faktorom streamovania. Súdiac podľa čítania RivaTuner, robotický proces nemal viac ako 154 MB video pamäte. Program TMPGEnc je jedným z tých, ktorí zavádzajú technológiu CUDA do počítačov Mac. Použitie GPU v tomto programe vám umožňuje urýchliť proces spracovania videa a výrazne upgradovať centrálny procesor, čo vám umožní pohodlne sa venovať iným úlohám súčasne. V našej konkrétnej aplikácii grafická karta GeForce 8800GT 256 MB mierne zlepšila takty pri konverzii videa založenom na procesore Pentium Dual-Core E5200. Je tiež jasne viditeľné, že s nižšou frekvenciou sa zvýši nárast aktivácie CUDA, na slabých procesoroch sa zvýšenie frekvencie zvýši viac. Na základe takéhoto poklesu je logické predpokladať, že s nárastom počtu dodatočných videofiltrov (napríklad viac ako veľkého počtu dodatočných videofiltrov) budú výsledky systému CUDA vnímané ako výraznejšie delta rozdielu v hodine strávenej procesom kódovania. Nezabudnite tiež, že G92 v súčasnosti nie je najvýkonnejším čipom a modernejšie grafické karty poskytujú výrazne vyššiu produktivitu s podobnými doplnkami. Avšak, v procese robotických programov GPU, nie sú tam žiadne zapletenia a, ymovirno, rozpodіl oportunizmus ležať v konfigurácii pokožky je v poriadku, ale sám o sebe, v spojení medzi procesorom / grafickou kartou, ktorá môže dať väčší (resp. menšie) zvýšenie aktívnej CU. Have-yakom vpadku, tim, hto pratsyuє z veľkých záväzkov video, takáto technológia všetky rovnaké umožňujú výrazne ušetriť vašu hodinu. Je pravda, že CUDA si zatiaľ nezískal všadeprítomnú popularitu, ako napríklad softvérová bezpečnosť, ktorá funguje s rovnakou technológiou, namiesto toho, aby bola drahá. Softvér TMPGEnc 4.0 XPress, ktorý sme recenzovali, ešte túto technológiu neprijal. Jedno a to isté video by sa dalo niekoľkokrát prekódovať a potom by rýchlo, útočným spustením, zapojenie CUDA už dosiahlo 0 %. І tse jav je málo známy vipadkovy charakter na úplne iný operačné systémy Oh. Pozrelo sa aj na program, pri kódovaní vo formáte XviD sa inšpiroval kódovaním CUDA, no problémy s obľúbeným kodekom DivX neboli. Výsledkom je, že technológia CUDA doteraz umožňuje citeľne zvýšiť produktivitu osobných počítačov, menej pri rovnakých úlohách. Okrem toho sa rozsah takejto technológie rozšíri a proces zvyšovania počtu jadier vo vyšších procesoroch bude naznačovať nárast dopytu po paralelných výpočtoch v moderných softvérových doplnkoch. Nie nadarmo ostatní lídri v tomto odvetví spustili myšlienku spojenia CPU a GPU v rámci jednej zjednotenej architektúry (hádajte, či chcete reklamy AMD Fusion). Možno je CUDA jedným z krokov v procese tohto združenia.4.7. Prehľadávajte údaje a vyberte 16 bajtov
4.8. Bankové konflikty v pamäti, ktoré sú rozdelené


4.9. Minimalizácia presúvania dát Host<=>zariadenie
5. Prenosná matematická knižnica CPU/GPU
6
.
Literatúra
Model GPU sa vypočíta:
Pozrime sa na výpočet modelu GPU v správe. CUDA a mov C:
Samotná technológia CUDA (kompilátor nvcc.exe) prináša množstvo doplnkových rozšírení filmov v jazyku C, ktoré sú potrebné na písanie kódu pre GPU:
Ako už bolo povedané, špecifikátory funkcií sú priradené tak, ako sa volajú funkcie. Usyi v CUDA má 3 takéto špecifikátory:
Špecifikátory spustenia jadra sa používajú na popis počtu blokov, vlákien a pamäte, takže môžete vidieť, kedy je GPU spustené. Syntax na spustenie jadra môže vyzerať takto:
Samozrejme, samotný myKernelFunc je funkcia jadra (špecifikátor __global__). Môžete vynechať denný čas cyklu jadra, napríklad sharedMemSize a cudaStream.
Pred rečou sa gridDim і blockDim є tі sami zmіnі, yakі mi prenesie pri spustení jadra GPU, avšak v jadre smradu je možné iba čítať. CUDA Host API:
Predtým, ako použiť CUDA bez sprostredkovateľa na výpočet, je potrebné poznať takzvané hostiteľské API CUDA, pretože je to šťastie medzi CPU a GPU. Hostiteľské API CUDA možno rozdeliť na nízkoúrovňové API pod názvom CUDA driver API, ktoré poskytuje prístup k ovládaču do režimu CUDA, a vysokoúrovňové API - CUDA runtime API. Vo svojich aplikáciách upravujem runtime API CUDA. Pochopenie robota GPU:
Ako už bolo povedané, vlákno - bezperednіy vikonovets počítané. Aká je hodnosť rozparalelyuvannya počítanie medzi vláknami? Pozrime sa na robota o odobratom bloku.
Prejdime k písaniu kódu: // Funkcia sčítania dvoch vektorov
__global__ void addVector(float * left, float * right, float * result)
{
//Potrebujeme ID vlákna.
int idx = threadIdx.x;
výsledok = vľavo + vpravo;
}
#define VEĽKOSŤ 512
__host__ int main()
{
//Vidíme pamäť vektora
float * vec1 = nový plavák;
float * vec2 = nový plavák;
float * vec3 = nový plavák;
pre (int i = 0; i< SIZE; i++)
{
vec1[i] = i;
vec2[i] = i;
}
float * devVec1;
float * devVec2;
float * devVec3;
cudaMalloc((void **)&devVec1, sizeof (float) * SIZE);
cudaMalloc((void **)&devVec2, sizeof (float) * SIZE);
cudaMalloc((void **)&devVec3, sizeof (float) * SIZE);
cudaMemcpy(devVec1, vec1, sizeof (float) * SIZE, cudaMemcpyHostToDevice);
cudaMemcpy(devVec2, vec2, sizeof (float) * SIZE, cudaMemcpyHostToDevice);
…
}
* Zdrojový kód Tsei bol zvýraznený pomocou Zvýrazňovača zdrojového kódu.
cudaError_t cudaMalloc(void** devPtr, veľkosť_t počet), de
Otočiť:
Na skopírovanie údajov z hádanky o grafickej karte sa používa cudaMemcpy ako možný prototyp:
cudaError_t cudaMemcpy(void* dst, const void* src ,size_t count, enum cudaMemcpyKind druh), de
Otočiť:
Teraz prejdime k nie prechodnému cyklu jadra pre výpočet GPU. …
dim3 gridSize = dim3(1, 1, 1); //Rozprestieranie víťaznej mriežky
dim3 blockSize = dim3(SIZE, 1, 1); //Rozmery zlého bloku
addVector<<
…
* Zdrojový kód Tsei bol zvýraznený pomocou Zvýrazňovača zdrojového kódu.
V našom prípade je potrebné priradiť mriežku k bloku, ktorý je neobov'yazkovo, aby bolo možné vyhrať iba jeden blok a jeden blok, takže môžete napísať kód: addVector<<<1, SIZE>>>(devVec1, devVec2, devVec3);
Teraz musíme skopírovať výsledok vyšetrovania z videopamäte do hostiteľskej hádanky. Funkcie jadra, ak existujú, však majú špeciálnu vlastnosť - asynchrónne hackovanie, takže po tom, čo cyklus jadra začne pracovať na ďalšom kroku v kóde, to ešte neznamená, že GPU prerušilo hodiny. Na dokončenie práce danej funkcie jadra je potrebné vyladiť funkcie synchronizácie, napríklad udalosti. Preto pred skopírovaním výsledkov do hostiteľa musíme synchronizovať vlákna GPU prostredníctvom udalosti. //weekclick na funkciu jadra
addVector<<
cudaEvent_t syncEvent;
cudaEventRecord(syncEvent, 0); //Napíšte udalosť
cudaEventSynchronize(syncEvent); // Synchronizovaná udalosť
cudaMemcpy(vec3, devVec3, sizeof (float) * SIZE, cudaMemcpyDeviceToHost);
* Zdrojový kód Tsei bol zvýraznený pomocou Zvýrazňovača zdrojového kódu.
Poďme sa pozrieť na funkcie Event Management API.
cudaError_t cudaEventCreate(cudaEvent_t* udalosť), de
Otočiť:
Záznam udalosti cudaEventRecord, prototyp je možné vidieť:
cudaError_t cudaEventRecord(udalosť cudaEvent_t, stream CUstream), de
Otočiť:
Synchronizácia udalosti je potlačená funkciou cudaEventSynchronize. Funkcia je daná na kontrolu dokončenia práce všetkých vlákien GPU a prechodu danej udalosti a potom nám stačí skontrolovať riadiaci program, ktorý volá. Funkčný prototyp môže vyzerať takto:
cudaError_t cudaEventSynchronize(udalosť cudaEvent_t), de
Otočiť:
Ak chcete pochopiť, ako používať cudaEventSynchronize, môžete použiť nasledujúcu schému: //Výsledky rosrahunu
pre (int i = 0; i< SIZE; i++)
{
printf("Prvok #%: %.1f\n" , i , vec3[i]);
}
// Zabudnite na zdroje
//
cudaFree(devVec2);
cudaFree(devVec3);
vymazať vec2; vec2 = 0;
vymazať vec3; vec3 = 0;
* Zdrojový kód Tsei bol zvýraznený pomocou Zvýrazňovača zdrojového kódu.
Myslím si, že nie je potrebné popisovať funkcie rozvoja zdrojov. Hiba scho, môžeš hádať, aký smrad invertuje hodnoty cudaError_t, pretože je potrebné znova overiť їх robotov. Višňovok
Som si istý, že tento materiál vám pomôže pochopiť, ako funguje GPU. Popísal som najdôležitejšie momenty, ktoré je potrebné poznať pre prácu s CUDA. Skúste si sami napísať sčítanie dvoch matíc, ale nezabudnite na hardvérovú výmenu grafickej karty.
PS: Pýtajte sa.
Diagram ukazuje dynamiku rastu produktivity CPU a GPU od roku 2003. Ak to máte radi, vložte to ako reklamu do svojich dokumentov NVIDIA, ale zápach je len teoretická karta a skutočne končí, samozrejme, môže sa zdať bohatší, než je.
CUDA je hack na programovanie štandardného mov C, čo je jedna z hlavných výhod pre vývojárov. Jadro CUDA obsahuje knižnice BLAS (Basic Linear Algebra Programming Package) a FFT (Fur's Development Fusion). Tiež schopnosť CUDA interagovať s grafickými API OpenGL alebo DirectX, schopnosť expandovať na nízkej úrovni, sa vyznačuje optimalizáciou distribúcie dátových tokov medzi CPU a GPU. Účty CUDA sa počítajú súčasne s grafikou na desktope na podobnej platforme AMD a spúšťa sa špeciálny virtuálny stroj na rozšírenie na GPU. Takáto „spіvzhity“ je však plná pardonov v čase veľkého nástupu grafického API s hodinovým robotom CUDA - aj keď grafické operácie môžu byť stále vyššou prioritou. Platforma je kompatibilná s 32-bitovými a 64-bitovými operačnými systémami Windows XP, Windows Vista, MacOS X a ďalšími verziami Linuxu. Platforma je k dispozícii na stránke, kde sú špeciálne ovládače pre grafickú kartu, môžete si stiahnuť CUDA Toolkit, softvérové balíky CUDA Developer SDK, ktoré zahŕňajú kompilátor, nalagodzhuvach, štandardné knižnice a dokumentáciu. 


Na rozdiel od referenčných modelov naša kópia pracuje na vyšších frekvenciách: rastrová doména je o 63 MHz vyššia ako nominálna a shaderové bloky sú o 174 MHz rýchlejšie, pamäť je o 100 MHz vyššia.
Pre testy je procesor do 3 GHz (pre konfiguráciu 11,5 × 261 MHz) a do 4 GHz (11,5 × 348 MHz) pri frekvencii RAM 835 MHz pri prvom a druhom type. Videoklip s inou budovou Full HD 1920x1080 na jeden úsek dvadsiatich sekúnd. Na vytvorenie dodatočného filtra na redukciu šumu sa zapol filter na redukciu šumu, ktorý bol odstránený kvôli uzamknutiu. 
Kódovanie bolo vykonané pomocou kodeku DivX 6.8.4. V nastaveniach kvality kodeku sú všetky hodnoty nadbytočné pre zamykanie, viacvláknové inklúzie. 
Možnosť bohatého vlákna TMPGEnc je zapnutá na karte nastavení CPU/GPU. Ktorá vetva je aktivovaná a CUDA. 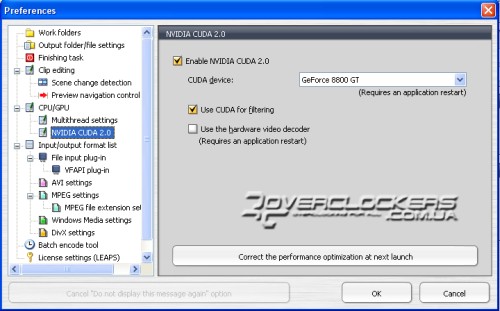
Ako môžete vidieť na snímke obrazovky, spracovanie filtra pre pomoc CUDA je aktivované a hardvérový dekodér videa nie je povolený. V dokumentácii pred programom sa odporúča, aby sa aktivácia zostávajúceho parametra vykonala pred predĺžením času spracovania súboru. 
S frekvenciou procesora 4 GHz sme s aktiváciou CUDA hrali len pár sekúnd (resp. 2 %), čo nie je ešte horšie. A os na nižšej frekvencii sa zvyšuje v dôsledku aktivácie tejto technológie vám umožňuje ušetriť asi 13% za hodinu, čo bude užitočné pri spracovaní veľkých súborov. Ale napriek tomu výsledky nie sú také nepriateľské, ako keby to bolo jasné. 
Višnovki
Vzhľadom na to, že prichádzajú spoločnosti na vlastné testovanie: