SAS, NAS, SAN: крок до мереж зберігання даних
вступ
З повсякденним ускладненням мережевих комп'ютерних систем і глобальних корпоративних рішень світ почав вимагати технологій, які б дали поштовх до відродження корпоративних системзберігання інформації (сторедж-систем). І ось, одна єдина технологія приносить в світову скарбницю досягнень в області сторедж небачене раніше швидкодію, колосальні можливості масштабування і виняткові переваги загальної вартості володіння. Обставини, які сформувалися з появою стандарту FC-AL (Fibre Channel - Arbitrated Loop) і SAN (Storage Area Network), Яка розвивається на його основі, обіцяють революцію в дата-орієнтованих технологіях комп'ютингу.
«The most significant development in storage we" ve seen in 15 years »
Data Communications International, March 21, 1998.
Формальне визначення SAN в трактуванні Storage Network Industry Association (SNIA):
«Мережа, головним завданням якої є передача даних між комп'ютерними системами і пристроями зберігання даних, а також між самими сторедж-системами. SAN складається з комунікаційної інфраструктури, яка забезпечує фізичну зв'язок, а також відповідає за рівень управління (management layer), який об'єднує зв'язку, сторедж і комп'ютерні системи, здійснюючи передачу даних безпечно і надійно ».
SNIA Technical Dictionary, copyright Storage Network Industry Association, 2000.
Варіанти організації доступу до сторедж-системам
Розрізняють три основні варіанти організації доступу до систем зберігання:
- SAS (Server Attached Storage), сторедж, приєднаний до сервера;
- NAS (Network Attached Storage), сторедж, приєднаний до мережі;
- SAN (Storage Area Network), мережа зберігання даних.
Розглянемо топології відповідних сторедж-систем та їх особливості.
SAS
Сторедж-система, приєднана до сервера. Знайомий усім, традиційний спосібпідключення системи зберігання даних до високошвидкісного інтерфейсу в сервері, як правило, до паралельного SCSI інтерфейсу.
Малюнок 1. Server Attached Storage
Використання окремого корпусу для сторедж-системи в рамках топології SAS не є обов'язковим.
Основна перевага сторедж, приєднаного до сервера, в порівнянні з іншими варіантами - низька ціна і висока швидкодія з розрахунку один сторедж для одного сервера. Така топологія є найоптимальнішою в разі використання одного сервера, через який організовується доступ до масиву даних. Але у неї залишається ряд проблем, які спонукали проектувальників шукати інші варіанти організації доступу до систем зберігання даних.
До особливостей SAS можна віднести:
- Доступ до даних залежить від ОС і файлової системи(у загальному випадку);
- Складність організації систем з високою готовністю;
- Низька вартість;
- Висока швидкодія в рамках однієї ноди;
- Зменшення швидкості відгуку при завантаженні сервера, який обслуговує сторедж.
NAS
Сторедж-система, під'єднана до мережі. Цей варіант організації доступу з'явився порівняно недавно. Основною його перевагою є зручність інтеграції додаткової системи зберігання даних в існуючі мережі, але сам по собі він не привносить хоч трохи радикальних поліпшень в архітектуру сторедж. Фактично NAS є чистий файл-сервер, і сьогодні можна зустріти чимало нових реалізацій сторедж типу NAS на основі технології тонкого сервера (Thin Server).

Малюнок 2. Network Attached Storage.
Особливості NAS:
- Виділений файл-сервер;
- Доступ до даних не залежить від ОС і платформи;
- Зручність адміністрування;
- Максимальна простота установки;
- Низька масштабованість;
- Конфлікт з трафіком LAN / WAN.
Сторедж, побудований за технологією NAS, є ідеальним варіантом для дешевих серверів з мінімальним набором функцій.
SAN
Мережі зберігання даних почали інтенсивно розвиватися і впроваджуватися лише з 1999 року. Основою SAN є окрема від LAN / WAN мережу, яка служить для організації доступу до даних серверів і робочих станцій, що займаються їх прямий обробкою. Така мережа створюється на основі стандарту Fibre Channel, що дає сторедж-системам переваги технологій LAN / WAN і можливості по організації стандартних платформ для систем з високою готовністю і високою інтенсивністю запитів. Майже єдиним недоліком SAN на сьогодні залишається відносно висока ціна компонент, але при цьому загальна вартість володіння для корпоративних систем, побудованих з використанням технології мереж зберігання даних, є досить низькою.

Малюнок 3. Storage Area Network.
До основних переваг SAN можна віднести практично всі її особливості:
- Незалежність топології SAN від сторедж-систем і серверів;
- Зручне централізоване управління;
- Відсутність конфлікту з трафіком LAN / WAN;
- Зручне резервування даних без завантаження локальної мережі і серверів;
- Висока швидкодія;
- Висока масштабованість;
- Висока гнучкість;
- Висока готовність і відмовостійкість.
Слід також зауважити, що технологія ця ще досить молода і найближчим часом вона повинна пережити чимало удосконалень в області стандартизації управління і способів взаємодії SAN підмереж. Але можна сподіватися, що це загрожує піонерам лише додатковими перспективами першості.
FC як основа побудови SAN
Подібно LAN, SAN може створюватися з використанням різних топологій і носіїв. При побудові SAN може використовуватися як паралельний SCSI інтерфейс, так і Fibre Channel або, скажімо, SCI (Scalable Coherent Interface), але своєї все зростаючою популярністю SAN зобов'язана саме Fibre Channel. У проектуванні цього інтерфейсу брали участь фахівці зі значним досвідом у розробці як канальних, так і мережевих інтерфейсів, і їм вдалося об'єднати всі важливі позитивні риси обох технологій для того, щоб отримати щось справді революційно нове. Що саме?
Основні ключові особливостіканальних:
- низькі затримки
- високі швидкості
- висока надійність
- Топологія точка-точка
- Невеликі відстані між нодамі
- Залежність від платформи
- багатоточкові топології
- великі відстані
- висока масштабованість
- низькі швидкості
- великі затримки
- високі швидкості
- Незалежність від протоколу (0-3 рівні)
- великі відстані
- низькі затримки
- висока надійність
- висока масштабованість
- багатоточкові топології
Традиційно сторедж інтерфейси (то, що знаходиться між хостом і пристроями зберігання інформації) були перешкодою на шляху до зростання швидкодії і збільшення обсягу систем зберігання даних. У той же час прикладні завдання вимагають значного приросту апаратних потужностей, які, в свою чергу, тягнуть за собою потребу в збільшенні пропускної здатності інтерфейсів для зв'язку з сторедж-системами. Саме проблеми побудови гнучкого високошвидкісного доступу до даних допомагає вирішити Fibre Channel.
Стандарт Fibre Channel був остаточно визначений за останні кілька років (з 1997-го по 1999-й), на протязі яких була проведена колосальна робота по узгодженню взаємодії виробників різних компонент, і було зроблено все необхідне, щоб Fibre Channel перетворився з чисто концептуальної технології в реальну, яка отримала підтримку у вигляді інсталяцій в лабораторіях і обчислювальних центрах. У році 1997 були спроектовані перші комерційні зразки наріжних компонент для побудови SAN на базі FC, таких як адаптери, хаби, свічі і мости. Таким чином, вже починаючи з 1998-го року FC використовується в комерційних цілях в діловій сфері, на виробництві і в масштабних проектах реалізації систем, критичних до відмов.
Fibre Channel - це відкритий промисловий стандарт високошвидкісного послідовного інтерфейсу. Він забезпечує підключення серверів і сторедж-систем на відстані до 10 км (при використанні стандартного оснащення) на швидкості 100 MB / s (на виставці Cebit "2000 було представлено зразки продукції, які використовують новий стандарт Fibre Channel зі швидкостями 200 MB / s на одне кільце, а в лабораторних умовах вже експлуатуються реалізації нового стандарту зі швидкостями 400 MB / s, що становить 800 MB / s при використанні подвійного кільця). (на момент публікації статті ряд виробників вже почав відвантажувати мережеві картки і свічі на FC 200 MB / s .) Fibre Channel одночасно підтримує цілий ряд стандартних протоколів (серед яких TCP / IP і SCSI-3) при використанні одного фізичного носія, Який потенційно спрощує побудову мережевої інфраструктури, до того ж це надає можливості для зменшення вартості монтажу та обслуговування. Проте використання окремих підмереж для LAN / WAN і SAN має ряд переваг і є рекомендованим за замовчуванням.
Одним з найважливіших переваг Fibre Channel поряд зі швидкісними параметрами (які, до речі, не завжди є головними для користувачів SAN і можуть бути реалізовані за допомогою інших технологій) є можливість роботи на великих відстанях і гнучкість топології, яка прийшла в новий стандарт з мережевих технологій. Таким чином, концепція побудови топології мережі зберігання даних базується на тих же принципах, що і традиційні мережі, як правило, на основі концентраторів і комутаторів, які допомагають запобігти падінню швидкості при зростанні кількості нод і створюють можливості зручної організації систем без єдиної точки відмов.
Для кращого розуміння переваг і особливостей цього інтерфейсу наведемо порівняльну характеристику FC і Parallel SCSI у вигляді таблиці.
Таблиця 1. Порівняння технологій Fibre Channel і паралельного SCSI
У стандарті Fibre Channel передбачається використання різноманітних топологій, таких як точка-точка (Point-to-Point), кільце або FC-AL концентратор (Loop або Hub FC-AL), магістральний комутатор (Fabric / Switch).
Топологія point-to-point використовується для під'єднання одиночної сторедж-системи до сервера.
Loop або Hub FC-AL - для під'єднання множинних сторедж пристроїв до декількох хостів. При організації подвійного кільця збільшується швидкодія і відмовостійкість системи.
Комутатори використовуються для забезпечення максимальної швидкодії і відмовостійкості для складних, великих і розгалужених систем.
Завдяки мережевий гнучкості в SAN закладена надзвичайно важлива особливість - зручна можливість побудови відмовостійких систем.
Пропонуючи альтернативні рішення для систем зберігання даних і можливості по об'єднанню декількох сторедж для резервування апаратних засобів, SAN допомагає забезпечувати захист апаратно-програмних комплексів від апаратних збоїв. Для демонстрації наведемо приклад створення двухнодовой системи без точок відмов.
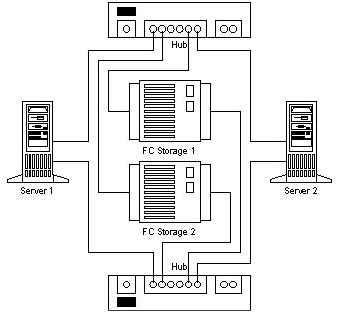
Малюнок 4. No Single Point of Failure.
Побудова трьох-і більше нодів систем здійснюється простим додаванням в FC мережу додаткових серверів і підключенням їх до обох концентраторів / комутаторів).
При використанні FC побудова стійких до збоїв (disaster tolerant) систем стає прозорим. Мережеві канали та для сторедж, і для локальної мережі можна прокласти на основі оптоволокна (до 10 км і більше з використанням підсилювачів сигналу) як фізичного носія для FC, при цьому використовується стандартна апаратура, яка дає можливість значно зменшити вартість подібних систем.
Завдяки можливості доступу до всіх компонентів SAN з будь-якої її точки ми отримуємо надзвичайно гнучко керовану мережу даних. При цьому слід зауважити, що в SAN забезпечується прозорість (можливість бачити) усіх компонентів аж до дисків в сторедж-системах. Ця особливість підштовхнула виробників компонентів до використання свого значного досвіду в побудові систем управління для LAN / WAN з тим, щоб закласти широкі можливості з моніторингу та управління в усі компоненти SAN. Ці можливості включають в себе моніторинг і управління окремих нод, сторедж компонентів, корпусів, мережевих пристроїв і мережевих підструктур.
В системі управління і моніторингу SAN використовуються такі відкриті стандарти, як:
- SCSI command set
- SCSI Enclosure Services (SES)
- SCSI Self Monitoring Analysis and Reporting Technology (S.M.A.R.T.)
- SAF-TE (SCSI Accessed Fault-Tolerant Enclosures)
- Simple Network Management Protocol (SNMP)
- Web-Based Enterprise Management (WBEM)
Системи, побудовані з використанням технологій SAN, не тільки забезпечують адміністратору можливість стежити за розвитком і станом сторедж ресурсів, а й відкривають можливості з моніторингу та контролю трафіку. Завдяки таким ресурсам програмні засоби управління SAN реалізують найбільш ефективні схеми планування обсягу сторедж і балансування навантаження на компоненти системи.
Мережі зберігання даних прекрасно інтегруються в існуючі інформаційні інфраструктури. Їх впровадження не вимагає яких-небудь змін в уже існуючих мережах LAN і WAN, а лише розширює можливості існуючих систем, позбавляючи їх від завдань, орієнтованих на передачу великих обсягів даних. Причому при інтеграції та адмініструванні SAN дуже важливим є те, що ключові елементи мережі підтримують гарячу заміну і установку, з можливостями динамічного конфігурування. Так що додати той чи інший компонент або здійснити його заміну адміністратор може, не вимикаючи систему. І весь цей процес інтеграції може бути візуально відображений в графічній системіуправління SAN.
Розглянувши перераховані вище переваги, можна виділити ряд ключових моментів, які безпосередньо впливають на одне з основних переваг Storage Area Network - загальну вартість володіння (Total Cost Ownership).
Неймовірні можливості масштабування дозволяють підприємству, яке використовує SAN, вкладати гроші в сервери і сторедж в міру необхідності. А також зберегти свої вкладення в уже инсталлированную техніку при зміні технологічних поколінь. кожен новий серверматиме можливість високошвидкісного доступу до сторедж і кожен додатковий гігабайт сторедж буде доступний всім серверам підмережі по команді адміністратора.
Прекрасні можливості з побудови відмовостійких систем можуть приносити пряму комерційну вигоду від мінімізації простоїв і рятувати систему в разі виникнення стихійного лиха або якихось інших катаклізмів.
Керованість компонентів і прозорість системи надають можливість здійснювати централізоване адміністрування всіх сторедж ресурсів, а це, в свою чергу, значно зменшує витрати на їх підтримку, вартість якої, як правило, становить понад 50% від вартості обладнання.
Вплив SAN на прикладні завдання
Для того щоб нашим читачам стало зрозуміліше, наскільки практично корисні технології, які розглядаються в цій статті, наведемо кілька прикладів прикладних задач, які без використання мереж зберігання даних вирішувалися б неефективно, вимагали б колосальних фінансових вкладень або ж взагалі не вирішувалися б стандартними методами.
Резервування і відновлення даних (Data Backup and Recovery)
Використовуючи традиційний SCSI інтерфейс, користувач при побудові систем резервування та відновлення даних стикається з низкою складних проблем, які можна дуже просто вирішити, використовуючи технології SAN і FC.
Таким чином, використання мереж зберігання даних виводить рішення задачі резервування і відновлення на новий рівень і надає можливість здійснювати бекап в кілька разів швидше, ніж раніше, без завантаження локальної мережі і серверів роботою по резервуванню даних.
Кластеризація серверів (Server Clustering)
Однією з типових задач, для яких ефективно використовується SAN, є кластеризація серверів. Оскільки один з ключових моментів в організації високошвидкісних кластерних систем, які працюють з даними - це доступ до сторедж, то з появою SAN побудова многонодових кластерів на апаратному рівні вирішується простим додаванням сервера з підключенням до SAN (це можна зробити, навіть не вимикаючи системи, оскільки свічі FC підтримують hot-plug). При використанні паралельного SCSI інтерфейсу, можливості по приєднанню і масштабованість якого значно гірше, ніж у FC, кластери, орієнтовані на обробку даних, було б важко зробити з кількістю нод більше двох. Комутатори паралельного SCSI - вельми складні і дорогі пристрої, А для FC це один зі стандартних компонентів. Для створення кластера, який не матиме жодної точки відмов, досить інтегрувати в систему дзеркальну SAN (технологія DUAL Path).
В рамках кластеризації одна з технологій RAIS (Redundant Array of Inexpensive Servers) здається особливо привабливою для побудови потужних масштабованих систем інтернет-комерції та інших видів завдань з підвищеними вимогами до потужності. За словами Alistair A. Croll, співзасновника Networkshop Inc, використання RAIS виявляється досить ефективним: «Наприклад, за $ 12000-15000 ви можете купити близько шести недорогих одно-двопроцесорних (Pentium III) Linux / Apache серверів. Потужність, масштабованість і відмовостійкість такої системи буде значно вище, ніж, наприклад, у одного чотирипроцесорні сервера на базі процесорів Xeon, а вартість однакова ».
Одночасний доступ до відео і розподіл даних (Concurrent video streaming, data sharing)
Уявіть собі задачу, коли вам потрібно на декількох (скажімо,> 5) станціях редагувати відео або просто працювати над даними величезного обсягу. Передача файлу розміром 100GB по локальній мережі забере у вас кілька хвилин, а спільна роботанад ним буде дуже складним завданням. При використанні SAN кожна робоча станція і сервер мережі отримують доступ до файлу на швидкості, еквівалентній локальному високошвидкісного диску. Якщо вам потрібні ще одна станція / сервер для обробки даних, ви зможете її додати до SAN, не вимикаючи мережі, простим підключенням станції до SAN комутатора і наданням їй прав доступу до сторедж. Якщо ж вас перестане задовольняти швидкодію підсистеми даних, ви зможете просто додати ще один сторедж і з використанням технології розподілу даних (наприклад, RAID 0) отримати вдвічі більшу швидкодію.
Основні компоненти SAN
середа
Для з'єднання компонентів в рамках стандарту Fibre Channel використовують мідні та оптичні кабелі. Обидва типи кабелів можуть використовуватися одночасно при побудові SAN. Конверсія інтерфейсів здійснюється за допомогою GBIC (Gigabit Interface Converter) і MIA (Media Interface Adapter). Обидва типи кабелю сьогодні забезпечують однакову швидкість передачі даних. Мідний кабель використовується для коротких відстаней (до 30 метрів), оптичний - як для коротких, так і для відстаней до 10 км і більше. Використовують багатомодовий і одномодовий оптичні кабелі. Багатомодовий (Multimode) кабель використовується для коротких відстаней (до 2 км). Внутрішній діаметр оптоволокна мультимодових кабелю становить 62,5 або 50 мікрон. Для забезпечення швидкості передачі 100 МБ / с (200 МБ / с в дуплексі) при використанні багатомодового оптоволокна довжина кабелю не повинна перевищувати 200 метрів. Одномодовий кабель використовується для великих відстаней. Довжина такого кабелю обмежена потужністю лазера, який використовується в передавачі сигналу. Внутрішній діаметр оптоволокна одномодового кабелю становить 7 або 9 мікрон, він забезпечує проходження одиночного променя.
Коннектори, адаптери
Для під'єднання мідних кабелів використовуються конектори типу DB-9 або HSSD. HSSD вважається більш надійним, але DB-9 використовується так само часто, тому що він більш простий і дешевий. Стандартним (найбільш поширеним) коннектором для оптичних кабелів є SC коннектор, він забезпечує якісне, чітке з'єднання. Для звичайного підключення використовуються багатомодові SC коннектори, а для віддаленого - одномодові. У багатопортових адаптери використовуються мікроконнектори.
Найбільш поширені адаптери для FC під шину PCI 64 bit. Також багато FC адаптерів виробляється під шину S-BUS, для спеціалізованого використання випускаються адаптери під MCA, EISA, GIO, HIO, PMC, Compact PCI. Найпопулярніші - однопортові, зустрічаються дво- і чотирьохпортовий картки. На PCI адаптери, як правило, використовують DB-9, HSSD, SC коннектори. Також часто зустрічаються GBIC-based адаптери, які поставляються як з модулями GBIC, так і без них. Fibre Channel адаптери відрізняються класами, які вони підтримують, і різноманітними особливостями. Для розуміння відмінностей наведемо порівняльну таблицю адаптерів виробництва фірми QLogic.
| Fibre Channel Host Bus Adapter Family Chart | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SANblade | 64 Bit | FCAL Publ. Pvt Loop | FL Port | Class 3 | F Port | Class 2 | Point to Point | IP / SCSI | Full Duplex | FC Tape | PCI 1.0 Hot Plug Spec | Solaris Dynamic Reconfig | VIв | 2Gb |
| 2100 Series | 33 & 66MHz PCI | X | X | X | ||||||||||
| 2200 Series | 33 & 66MHz PCI | X | X | X | X | X | X | X | X | X | ||||
| 33MHz PCI | X | X | X | X | X | X | X | X | X | X | ||||
| 25 MHZ Sbus | X | X | X | X | X | X | X | X | X | X | ||||
| 2300 Series | 66 MHZ PCI / 133MHZ PCI-X | X | X | X | X | X | X | X | X | X | X | X | ||
концентратори
Fibre Channel HUBs (концентратори) використовуються для підключення нод до FC кільцю (FC Loop) і мають структуру, схожу на Token Ring концентратори. Оскільки розрив кільця може привести до припинення функціонування мережі, в сучасних FC концентраторах використовуються порти обходу кільця (PBC-port bypass circuit), які дозволяють автоматично відкривати / закривати кільце (підключати / відключати системи, приєднані до концентратора). Зазвичай FC HUBs підтримують до 10 підключень і можуть стекіроваться до 127 портів на кільце. Всі пристрої, підключені до HUB, отримують загальну смугу пропускання, яку вони можуть розділяти між собою.
комутатори
Fibre Channel Switches (комутатори) мають ті ж функції, що і звичні читачеві LAN комутатори. Вони забезпечують повношвидкісне неблокірованние підключення між нодамі. Будь-яка нода, підключена до FC комутатора, отримує повну (з можливостями масштабування) смугу пропускання. При збільшенні кількості портів комутованого мережі її пропускна здатність збільшується. Комутатори можуть використовуватися разом з концентраторами (які використовують для ділянок, які не потребують виділеної смуги пропускання для кожної ноди) для досягнення оптимального співвідношення ціна / продуктивність. Завдяки каскадування свічі потенційно можуть використовуватися для створення FC мереж з кількістю адрес 2 24 (понад 16 мільйонів).
мости
FC Bridges (мости або мультиплексори) використовуються для підключення пристроїв з паралельним SCSI до мережі на базі FC. Вони забезпечують трансляцію SCSI пакетів між Fibre Channel і Parallel SCSI пристроями, прикладами яких можуть служити Solid State Disk (SSD) або бібліотеки на магнітних стрічках. Слід зауважити, що останнім часом практично всі пристрої, які можуть бути утилізовані в рамках SAN, виробники починають випускати з вмонтованим FC інтерфейсом для прямого їх підключення до мереж зберігання даних.
Сервери та сторедж
Незважаючи на те що сервери і сторедж - далеко не останні за важливістю компоненти SAN, ми на їх описі зупинятися не будемо, оскільки впевнені, що з ними добре знайомі всі наші читачі.
В кінці хочеться додати, що ця стаття - лише перший крок до мереж зберігання даних. Для повного розуміння теми читачеві слід приділити чимало уваги особливостям реалізації компонент виробниками SAN і програмних засобів управління, оскільки без них Storage Area Network - це всього лише набір елементів для комутації сторедж-систем, які не принесуть вам повноти переваг від реалізації мережі зберігання даних.
висновок
Сьогодні Storage Area Network є досить новою технологією, яка незабаром може стати масовою в колі корпоративних замовників. У Європі та США підприємства, які мають досить великий парк інстальованих сторедж-систем, вже починають переходити на мережі зберігання даних для організації сторедж з найкращим показником загальної вартості володіння.
За прогнозами аналітиків, в 2005 році значна кількість серверів середнього та верхнього рівня будуть поставлятися з попередньо встановленим інтерфейсом Fibre Channel (таку тенденцію можна помітити вже сьогодні), і лише для внутрішнього підключення дисків в серверах буде використовуватися паралельний SCSI інтерфейс. Вже сьогодні при побудові сторедж-систем і придбанні серверів середнього та верхнього рівня слід звернути увагу на цю перспективну технологію, тим більше, що вже сьогодні вона дає можливість реалізувати ряд завдань куди дешевше, ніж за допомогою спеціалізованих рішень. Крім того, вкладаючи в технологію SAN сьогодні, ви не втратите свої вкладення завтра, оскільки особливості Fibre Channel створюють прекрасні можливості для використання в майбутньому вкладених сьогодні інвестицій.
P.S.
Попередня версія статті була написана в червні 2000 року, але у зв'язку з відсутністю масового інтересу до технології мереж зберігання даних публікація була відкладена на майбутнє. Це майбутнє настав сьогодні, і я сподіваюся, що дана стаття спонукає читача усвідомити необхідність переходу на технологію мереж зберігання даних, як передову технологію побудови сторедж-систем і організації доступу до даних.
Що таке системи зберігання даних (СЗД) і для чого вони потрібні? У чому різниця між iSCSI і FibreChannel? Чому дане словосполучення тільки в останні роки стало відомо широкому колу IT-фахівців і чому питання систем зберігання даних все більше і більше турбують вдумливі уми?
Думаю, багато хто помітив тенденції розвитку в навколишньому комп'ютерному світі- перехід від екстенсивної моделі розвитку до інтенсивної. Нарощування мегагерц процесорів вже не дає видимого результату, а розвиток накопичувачів не встигає за обсягом інформації. Якщо в разі процесорів все більш-менш зрозуміло - досить збирати багатопроцесорні системи та / або використовувати кілька ядер в одному процесорі, то в разі питань зберігання та обробки інформації так просто від проблем не позбутися. Існуюча на даний момент панацея від інформаційної епідемії - СГД. Назва розшифровується як мережа зберігання даних (Storage Area Network) або Система Зберігання Даних. У будь-якому випадку - це спе 
Основні проблеми, які вирішуються СГД
Отже, які ж завдання покликана вирішити СГД? Розглянемо типові проблеми, Пов'язані зі зростаючими обсягами інформації в будь-якій організації. Припустимо, що це хоча б кілька десятків комп'ютерів і кілька рознесених територіально офісів.
1. Децентралізація інформації- якщо раніше всі дані могли зберігатися буквально на одному жорсткому диску, то зараз будь-яка функціональна система вимагає окремого сховища - наприклад, серверів електронної пошти, СУБД, домену і так далі. Ситуація ускладнюється у разі розподілених офісів (філій).
2. Лавиноподібний зростання інформації- найчастіше кількість жорстких дисків, які ви можете встановити в конкретний сервер, не може покрити необхідну системі ємність. Як наслідок:
Неможливість повноцінно захистити збережені дані - дійсно, адже досить важко зробити навіть backup даних, які знаходяться не тільки на різних серверах, а й рознесені територіально.
Недостатня швидкість обробки інформації - канали зв'язку між віддаленими майданчиками поки залишають бажати кращого, але навіть при досить «товстому» каналі не завжди можливо повноцінне використанняіснуючих мереж, наприклад, IP, для роботи.
складність резервного копіювання- якщо дані читаються і записуються невеликими блоками, то зробити повне архівування інформації з віддаленого сервераза існуючими каналам може бути нереально - необхідна передача всього обсягу даних. Архівування на місцях часто недоцільно з фінансових міркувань - необхідні системи для резервного копіювання (стрічкові накопичувачі, наприклад), спеціальне програмне забезпечення (яке може коштувати чималих грошей), навчений і кваліфікований персонал.
3. Складно або неможливо передбачити необхідний обсяг дискового просторупри розгортанні комп'ютерної системи. Як наслідок:
Виникають проблеми розширення дискових ємностей - досить складно отримати в сервері ємності порядків терабайт, особливо якщо система вже працює на існуючих дисках невеликої ємності - як мінімум, потрібно зупинка системи і неефективні фінансові вкладення.
Неефективна утилізація ресурсів - часом не вгадати, в якому сервері дані будуть рости швидше. У сервері електронної пошти може бути вільний критично малий обсяг дискового простору, в той час як інший підрозділ буде використовувати всього лише 20% обсягу недешевої дискової підсистеми (наприклад, SCSI).
4. Низька ступінь конфіденційності розподілених даних- неможливо проконтролювати і обмежити доступ відповідно до політики безпеки підприємства. Це стосується як доступу до даних за існуючими для цього каналах (локальна мережа), так і фізичного доступудо носіїв - наприклад, не виключені розкрадання жорстких дисків, їх руйнування (з метою утруднити бізнес організації). Некваліфіковані дії користувачів і обслуговуючого персоналу можуть завдати ще більшої шкоди. Коли компанія в кожному офісі змушена вирішувати дрібні локальні проблеми безпеки, це не дає бажаного результату.
5. Складність управління розподіленими потоками інформації- будь-які дії, які спрямовані на зміни даних в кожній філії, що містить частину розподілених даних, створює певні проблеми, починаючи від складності синхронізації різних баз даних, версій файлів розробників і закінчуючи непотрібним дублюванням інформації.
6. Низький економічний ефект впровадження «класичних» рішень- у міру зростання інформаційної мережі, великих обсягів даних і все більш розподіленої структури підприємства фінансові вкладення виявляються не настільки ефективні і часто не можуть вирішити проблем, що виникають.
7. Високі витрати використовуваних ресурсів для підтримки працездатності всієї інформаційної системипідприємства - починаючи від необхідності утримувати великий штат кваліфікованого персоналу і закінчуючи численними недешевими апаратними рішеннями, які покликані вирішити проблему обсягів і швидкостей доступу до інформації укупі з надійністю зберігання і захистом від збоїв.
У світлі перерахованих вище проблем, які рано чи пізно, повністю або частково наздоганяють будь-яку динамічно розвивається, спробуємо окреслити системи зберігання даних - такими, якими вони повинні бути. Розглянемо типові схемипідключення і види систем зберігання даних.
Мегабайти / транзакції?
Якщо раніше жорсткі диски знаходилися всередині комп'ютера (сервера), то тепер їм там стало тісно і не дуже надійно. Найпростіше рішення (розроблене досить давно і застосовується повсюдно) - технологія RAID.
images \ RAID \ 01.jpg
При організації RAID в будь-яких системах зберігання даних додатково до захисту інформації ми отримуємо кілька незаперечних переваг, одне з яких - швидкість доступу до інформації.
З точки зору користувача або ПО, швидкість визначається не тільки пропускною здатністю системи (Мбайт / с), а й числом транзакцій - тобто числом операцій введення-виведення в одиницю часу (IOPS). Збільшенню IOPS сприяє, що цілком логічно, більше число дисків і ті методики підвищення продуктивності, які надає контролер RAID(Наприклад, кешування).
Якщо для перегляду потокового відео або організації файл-сервера більше важлива загальна пропускна здатність, то для СУБД, будь-яких OLTP (online transaction processing) додатків критично саме число транзакцій, які здатна обробляти система. А з цим параметром у сучасних жорстких дисків все не так райдужно, як зі зростаючими обсягами і, частково, швидкостями. Всі ці проблеми покликана вирішити сама система зберігання даних.
рівні захисту
Потрібно розуміти, що в основі всіх систем зберігання даних лежить практика захисту інформації на базі технології RAID - без цього будь-яка технічно просунута СГД буде марна, бо жорсткі диски в цій системі є самим ненадійним компонентом. Організація дисків в RAID - це «нижня ланка», перший ешелон захисту інформації і підвищення швидкості обробки.
Однак, крім схем RAID, існує і більш низкоуровневая захист даних, реалізована «поверх» технологій і рішень, впроваджених в сам жорсткий дискйого виробником. Наприклад, у одного з провідних виробників СГД - компанії EMC - існує методика додаткового аналізу цілісності даних на рівні секторів накопичувача.
Розібравшись з RAID, перейдемо до структури самих СГД. Перш за все, СГД поділяються за типом використовуваних інтерфейсів підключення хостів (серверів). Зовнішні інтерфейси підключення - це, в основному SCSI або FibreChannel, а також досить молодий стандарт iSCSI. Також не варто скидати з рахунків невеликі інтелектуальні сховища, які можуть підключатися навіть по USB або FireWire. Ми не станемо розглядати більш рідкісні (часом просто невдалі в тому чи іншому плані) інтерфейси, як SSA від IBM або інтерфейси, розроблені для мейнфреймів - наприклад, FICON / ESCON. Окремо стоять сховища NAS, що підключаються до мережі Ethernet. Під словом «інтерфейс» в основному розуміється зовнішній роз'єм, але не варто забувати, що роз'єм не визначає протокол зв'язку двох пристроїв. На ці особливості ми зупинимося трохи нижче.
images \ RAID \ 02.gif
Розшифровується як Small Computer System Interface (читається «скази») - напівдуплексний паралельний інтерфейс. У сучасних системах зберігання даних найчастіше представлений роз'ємом SCSI:
images \ RAID \ 03.gif
images \ RAID \ 04.gif
І групою протоколів SCSI, а конкретніше - SCSI-3 Parallel Interface. Відмінність SCSI від знайомого нам IDE - більше число пристроїв на канал, більша довжина кабелю, більша швидкість передачі даних, а також «ексклюзивні» особливості типу high voltage differential signaling, command quequing і деякі інші - заглиблюватися в це питання ми не станемо.
Якщо говорити про основні виробниках компонент SCSI, наприклад SCSI-адаптерів, RAID-контролерів з інтерфейсом SCSI, то будь-який фахівець відразу пригадає дві назви - Аdaptec і LSI Logic. Думаю, цього досить, революцій на цьому ринку не було вже давно і, ймовірно, не передбачається.
інтерфейс FibreChannel
Повнодуплексний послідовний інтерфейс. Найчастіше в сучасному обладнанні представлений зовнішніми оптичними роз'ємами типу LC або SC (LC - менше за розмірами):
images \ RAID \ 05.jpg
images \ RAID \ 06.jpg
... і протоколами FibreChannel Protocols (FCP). Існує кілька схем комутації пристроїв FibreChannel:
Point-to-Point- точка-точка, пряме з'єднання пристроїв між собою:
images \ RAID \ 07.gif
Crosspoint Switched- підключення пристроїв в комутатор FibreChannel (аналогічне реалізації мережі Ethernet на комутаторах):
images \ RAID \ 08.gif
Arbitrated loop- FC-AL, петля з арбітражним доступом - всі пристрої зв'язані один з одним в кільце, схема чимось нагадує Token Ring. Також може використовуватися комутатор - тоді фізична топологія буде реалізована за схемою «зірка», а логічна - за схемою «петля» (або «кільце»):
images \ RAID \ 09.gif
Підключення за схемою FibreChannel Switched є найпоширенішою схемою, в термінах FibreChannel таке підключення називається Fabric - в російській мові існує калька з нього - «фабрика». Слід врахувати, що комутатори FibreChannel - це досить просунуті пристрої, за складністю наповнення близькі до IP-комутаторів рівня 3. Якщо комутатори з'єднані між собою, то вони функціонують в єдиній фабриці, маючи пул налаштувань, що діють для всієї фабрики відразу. Зміна якихось опцій на одному з комутаторів може призводити до перекоммутации всієї фабрики, не кажучи вже про налаштування авторизації доступу, наприклад. З іншого боку, існують схеми SAN, які мають на увазі кілька фабрик всередині єдиної мережі SAN. Таким чином, фабрикою можна називати тільки групу об'єднаних між собою комутаторів - два чи більше не об'єднаних між собою пристрої, введені в SAN для підвищення відмовостійкості, утворюють дві або більше різні фабрики.
Компоненти, що дозволяють об'єднувати хости і системи зберігання даних в єдину мережу, прийнято позначати терміном «connectivity». Connectivity - це, звичайно ж, дуплексні сполучні кабелі (зазвичай з інтерфейсом LC), комутатори (switches) і адаптери FibreChannel (HBA, Host Base Adapters) - тобто ті плати розширення, які, будучи встановленими в хости, дозволяють підключити хост в мережу SAN. HBA зазвичай реалізовані у вигляді плат стандарту PCI-X або PCI-Express.
images \ RAID \ 10.jpg
Не варто плутати fibre і fiber - середовище поширення сигналу може бути різною. FibreChannel може працювати по «міді». Наприклад, всі жорсткі диски FibreChannel мають металеві контакти, та й звичайна комутація пристроїв по «міді» - не рідкість, просто поступово всі переходять на оптичні канали як найбільш перспективну технологію і функціональну заміну «міді».
інтерфейс iSCSI
Зазвичай представлений зовнішнім роз'ємом RJ-45 для підключення в мережу Ethernet і власне самим протоколом iSCSI (Internet Small Computer System Interface). За визначенням SNIA: «iSCSI - це протокол, який базується на TCP / IP і розроблений для встановлення взаємодії і управління системами зберігання даних, серверами і клієнтами». На цьому інтерфейсі зупинимося трошки детальніше, хоча б в силу того, що кожен користувач здатний використовувати iSCSI навіть у звичайній «домашньої» мережі.
Необхідно знати, що протокол iSCSI визначає, як мінімум, транспортний протокол для SCSI, який працює поверх TCP, і технологію інкапсуляції SCSI-команд в мережу на базі IP. Простіше кажучи, iSCSI - це протокол, що дозволяє отримати блоковий доступ до даних за допомогою команд SCSI, що пересилаються через мережу зі стеком TCP / IP. iSCSI з'явився як заміна FibreChannel і в сучасних СГД має перед ним кілька переваг - здатність об'єднувати пристрої на великих відстанях (використовуючи існуючі мережі IP), можливість забезпечувати заданий рівень QoS (Quality of Service, якість обслуговування), нижчу вартість connectivity. Однак основна проблема використання iSCSI як заміни FibreChannel - великий час затримок, що виникають в мережі через особливості реалізації стека TCP / IP, що зводить нанівець одне з важливих переваг використання СГД - швидкість доступу до інформації та низьку латентність. Це серйозний мінус.
Маленьке зауваження з приводу хостів - вони можуть використовувати як звичайні мережеві карти(Тоді обробка стека iSCSI і інкапсуляція команд буде здійснюватися програмними засобами), так і спеціалізовані картиз підтримкою технологій аналогічних TOE (TCP / IP Offload Engines). Така технологія забезпечує апаратну обробку відповідної частини стека протоколу iSCSI. Програмний метод дешевше, однак більше завантажує центральний процесор сервера і в теорії може призводити до більшим затримок, ніж апаратний обробник. При сучасній швидкості мереж Ethernet в 1 Гбіт / с можна припустити, що iSCSI буде працювати рівно в два рази повільніше FibreChannel зі швидкістю 2 Гбіт, проте в реальному застосуванні різниця буде ще помітнішою.
Крім уже розглянутих, коротко згадаємо ще пару протоколів, які зустрічаються рідше і призначені для надання додаткових сервісів вже існуючих мереж зберігання даних (SAN):
FCIP (Fibre Channel over IP)- тунельний протокол, побудований на TCP / IP і призначений для з'єднання географічно рознесених мереж SAN через стандартну середу IP. Наприклад, можна об'єднати дві мережі SAN в одну через Інтернет. Досягається це використанням FCIP-шлюзу, який прозорий для всіх пристроїв в SAN.
iFCP (Internet Fibre Channel Protocol)- протокол, що дозволяє поєднувати пристрої з інтерфейсами FC через IP-мережі. Важлива відмінність від FCIP в тому, що можливо об'єднувати саме FC-пристрої через IP-мережу, що дозволяє для різної пари сполук мати різний рівень QoS, що неможливо при тунелюванні через FCIP.
Ми коротко розглянули фізичні інтерфейси, протоколи і типи комутації для систем зберігання даних, не зупиняючись на перерахування всіх можливих варіантів. Тепер спробуємо уявити які ж параметри характеризують системи зберігання даних?
Основні апаратні параметри СГД
Деякі з них були перераховані вище - це тип зовнішніх інтерфейсів підключення та типи внутрішніх накопичувачів(Жорстких дисків). Наступний параметр, який є сенс розглядати після двох перерахованих вище при виборі дискової системи зберігання, - її надійність. Надійність можна оцінити не за банальним часу напрацювання на відмову якихось окремих компонент(Факт, що цей час приблизно дорівнює у всіх виробників), а за внутрішньою архітектурою. «Звичайна» система зберігання часто «зовні» являє собою дискову полку (для монтажу в 19-дюймовий шафа) з жорсткими дисками, зовнішніми інтерфейсами для підключення хостів, декількома блоками харчування. Усередині зазвичай встановлено все те, що забезпечує роботу системи зберігання - процесорні блоки, контролери дисків, портів введення-виведення, кеш-пам'ять і так далі. Зазвичай управління стійкою здійснюється з командного рядка або по web-інтерфейсу, початкова конфігурація часто вимагає підключення по послідовному інтерфейсу. Користувач може «розбити» наявні в системі диски на групи і об'єднати їх в RAID (різних рівнів), що вийшло дисковий простір розділяється на один або кілька логічних блоків (LUN), до яких і мають доступ хости (сервери) і «бачать» їх як локальні жорсткі диски. Кількість RAID-груп, LUN-ів, логіка роботи кеша, доступність LUN-ів конкретним серверів і все інше встановлюється адміністратором системи. Зазвичай СГД призначені для підключення до них не одного, а декількох (аж до сотень, в теорії) серверів - тому така система повинна володіти високою продуктивністю, гнучкою системою управління і моніторингу, продуманими засобами захисту даних. Захист даних забезпечується багатьма способами, найпростіший з яких ви вже знаєте - об'єднання дисків в RAID. Однак дані повинні бути ще й постійно доступні - адже зупинка однієї системи зберігання даних, центральною на підприємстві, здатна нанести відчутні збитки. Чим більше систем зберігає дані на СГД, тим надійніший доступ до системи повинен бути забезпечений - тому що при аварії СГД зупиняється робота відразу всіх серверів, що зберігають там дані. Висока доступність стійки забезпечується повним внутрішнім дублюванням всіх компонент системи - шляхів доступу до стійки (портів FibreChannel), процесорних модулів, кеш-пам'яті, блоків живлення і т.д. Спробуємо принцип 100% -го резервування (дублювання) пояснити наступним малюнком:
images \ RAID \ 11.gif
1. Контролер (процесорний модуль) СГД, що включає в себе:
* Центральний процесор (або процесори) - зазвичай на системі працює спеціальне ПЗ, яке виконує роль «операційної системи»;
* Інтерфейси для комутації з жорсткими дисками - в нашому випадку це плати, що забезпечують підключення дисків FibreChannel за схемою петлі з арбітражним доступом (FC-AL);
* Кеш-пам'ять;
* Контролери зовнішніх портів FibreChannel
2. Зовнішній інтерфейс FC; як ми бачимо, тут їх по 2 штуки на кожен процесорний модуль;
3. Жорсткі диски- ємність розширюється додатковими дисковими полками;
4. Кеш-пам'ять в такій схемі зазвичай Віддзеркалюються, щоб не втратити збережені там дані при виході будь-якого модуля з ладу.
Відносно апаратної частини - дискові стійки можуть мати різні інтерфейси для підключення хостів, різні інтерфейси жорстких дисків, різні схеми підключення додаткових полиць, службовців для збільшення числа дисків в системі, а також інші чисто «залізні параметри».
Програмне забезпечення СГД
Природно, апаратна міць систем зберігання повинна якось справлятися, а самі СГД просто зобов'язані надавати рівень сервісу і функціональність, недоступну в звичайних схемах «сервер-клієнт». Якщо розглянути малюнок « Структурна схемасистеми зберігання даних », стає зрозуміло, що при прямому підключенні сервера до стійки двома шляхами вони повинні бути підключені до FC-портам різних процесорних модулів, для того щоб сервер продовжував працювати при виході з ладу відразу всього процесорного модуля. Природно, для використання multipathing повинна бути забезпечена підтримка цієї функціональності апаратними та програмними засобами всіх рівнів, які беруть участь в передачі даних. Звичайно ж, повне резервування без засобів моніторингу та оповіщення не має сенсу - тому всі серйозні системи зберігання мають такі можливості. Наприклад, оповіщення про будь-які критичні події може відбуватися різними засобами - це сповіщення по e-mail, автоматичний модемний дзвінок в центр техпідтримки, повідомлення на пейджер (зараз актуальніше SMS), SNMP-механізми та інше.
Ну і як ми вже згадували, існують потужні засоби управління всією цією пишністю. Зазвичай це web-інтерфейс, консоль, можливість писати скрипти і вбудовувати управління в зовнішні програмні пакети. Про механізми, що забезпечують високу продуктивність СГД, згадаємо лише коротко - неблокіруемая архітектура з декількома внутрішніми шинами і великою кількістю жорстких дисків, потужні центральні процесори, спеціалізована система управління (ОС), великий об'єм кеш-пам'яті, безліч зовнішніх інтерфейсів вводу-виводу.
Сервіси, що надаються системами зберігання, зазвичай визначаються програмним забезпеченням, що функціонує на самій дискової стійці. Практично завжди це складні програмні пакети, придбані за окремими ліцензіями, що не входять у вартість самої СГД. Відразу згадаємо вже знайоме вам ПО для забезпечення multipathing - ось воно як раз функціонує на хостах, а не на самій стійці.
Наступний за популярністю рішення - ПО для створення миттєвих і повних копій даних. Різні виробники по-різному називають свої програмні продуктиі механізми створення цих копій. Ми для узагальнення можемо маніпулювати словами снапшот (snapshot) і клон (clone). Клон робиться засобами дискової стійки усередині самої стійки - це повна внутрішня копія даних. Сфера застосування досить широка - від бекапа (backup) до створення «тестової версії» вихідних даних, наприклад, для ризикованих модернізацій, в яких немає впевненості і застосовувати які на актуальних даних небезпечно. Той, хто уважно стежив за всіма принадами СГД, які ми тут розбирали, запитає - для чого ж потрібен бекап даних всередині стійки, якщо вона володіє такою високою надійністю? Відповідь на це питання лежить на поверхні - ніхто не застрахований від людських помилок. Дані збережені надійно, але якщо сам оператор зробив щось не так, наприклад, видалив потрібну таблицю в базі даних, від цього не врятують жодні апаратні хитрощі. Клонування даних зазвичай виконується на рівні LUN. Більш цікава функціональність забезпечується механізмом снапшотов. В якійсь мірі ми отримуємо всі принади повної внутрішньої копії даних (клону), при цьому не займаючи 100% обсягу копійованих даних всередині самої стійки, адже такий обсяг нам не завжди доступний. По суті снапшот - миттєвий «знімок» даних, який не займає часу і процесорних ресурсів СГД.
Звичайно не можна не згадати ПО для реплікації (replication) даних, яке часто називають дзеркалюванням (mirroring). Це механізм синхронного або асинхронного реплицирования (дублювання) інформації з однієї системи зберігання на одну або кілька віддалених систем зберігання. Реплікація можлива по різних каналах - наприклад, стійки з інтерфейсами FibreChannel можуть асинхронно, через Інтернет і на великі відстані, реплицироваться на іншу СГД. Таке рішення забезпечує надійність зберігання інформації і захист від катастроф.
Крім всіх перерахованих, існує велика кількість інших програмних мехонізмов маніпуляцій даними ...
DAS & NAS & SAN
Після знайомства з самими системами зберігання даних, принципами їх побудови, наданими ними можливостями та протоколами функціонування саме час спробувати об'єднати отримані знання в працюючу схему. Спробуємо розглянути типи систем зберігання і топології їх підключення в єдину працюючу інфраструктуру.
пристрої DAS (Direct Attached Storage)- системи зберігання, що підключаються безпосередньо до сервера. Сюди відносяться як найпростіші SCSI-системи, що підключаються до SCSI / RAID-контролеру сервера, так і пристрої FibreChannel, підключені прямо до сервера, хоча і призначені вони для мереж SAN. В цьому випадку топологія DAS є вироджених SAN (мережею зберігання даних):
images \ RAID \ 12.gif
У цій схемі один з серверів має доступ до даних, що зберігаються на СГД. Клієнти отримують доступ до даних, звертаючись до цього сервера через мережу. Тобто сервер має блоковий доступ до даних на СГД, а вже клієнти користуються файловим доступом - ця концепція дуже важлива для розуміння. Мінуси такої топології очевидні:
* Низька надійність - при проблемах мережі або аварії сервера дані стають недоступними всім відразу.
* Висока латентність, обумовлена обробкою всіх запитів одним сервером і використовується транспортом (найчастіше - IP).
* Високе завантаження мережі, часто визначає межі масштабованості шляхом додавання клієнтів.
* Погана керованість - вся ємність доступна одного сервера, що знижує гнучкість розподілу даних.
* Низька утилізація ресурсів - важко передбачити необхідні обсяги даних, у одних пристроїв DAS в організації може бути надлишок ємності (дисків), у інших її може не вистачати - перерозподіл часто неможливо або трудомістким.
пристрої NAS (Network Attached Storage)- пристрої зберігання, підключені безпосередньо в мережу. На відміну від інших систем NAS забезпечує файловий доступ до даних і ніяк інакше. NAS-пристрої являють собою комбінацію системи зберігання даних і сервера, до якого вона підключена. У найпростішому варіанті звичайний мережевий сервер, що надає файлові ресурси, є пристроєм NAS:
images \ RAID \ 13.gif
Всі мінуси такої схеми аналогічні DAS-топології, за деяким винятком. З додав мінусів відзначимо збільшену, і часто значно, вартість - правда, вартість пропорційна функціональності, а тут вже часто «є за що платити». NAS-пристрої можуть бути найпростішими «коробочками» з одним портом ethernet і двома жорсткими дисками в RAID1, що дозволяють доступ до файлів по лише одному протоколу CIFS (Common Internet File System) до величезних систем в яких можуть бути встановлені сотні жорстких дисків, а файловий доступ забезпечується десятком спеціалізованих серверів всередині NAS-системи. Число зовнішніх Ethernet-портів може досягати багатьох десятків, а ємність збережених даних - кілька сотень терабайт (наприклад EMC Celerra CNS). Такі моделі по надійності і продуктивності можуть далеко обходити багато midrange-пристрої SAN. Що цікаво, NAS-пристрої можуть бути частиною SAN-мережі і не мати власних накопичувачів, а лише надавати файловий доступ до даних, що знаходяться на блокових пристроях зберігання. В такому випадку NAS бере на себе функцію потужного спеціалізованого сервера, а SAN - пристрої зберігання даних, тобто ми отримуємо топологію DAS, скомпоновану з NAS- і SAN-компонентів.
NAS-пристрої дуже гарні в гетерогенному середовищі, де необхідний швидкий файловий доступ до даних для багатьох клієнтів одночасно. Також забезпечується відмінна надійність зберігання і гнучкість управління системою укупі з простотою обслуговування. На надійності особливо зупинятися не будемо - це аспект СГД розглянуто вище. Що стосується гетерогенного середовища, доступ до файлів в рамках єдиної NAS-системи може бути отриманий за протоколами TCP / IP, CIFS, NFS, FTP, TFTP і іншим, включаючи можливість роботи NAS, як iSCSI-target, що забезпечує функціонування з різним ОС, встановленими на хостах. Що стосується легкості обслуговування і гнучкості управління, то ці можливості забезпечуються спеціалізованої ОС, яку важко вивести з ладу і не потрібно обслуговувати, а також простотою розмежування прав доступу до файлів. Наприклад, можлива робота в середовищі Windows Active Directory з підтримкою необхідної функціональності - це може бути LDAP, Kerberos Authentication, Dynamic DNS, ACLs, призначення квот (quotas), Group Policy Objects і SID-історії. Так як доступ забезпечується до файлів, а їх імена можуть містити символи різних мов, багато NAS забезпечують підтримку кодувань UTF-8, Unicode. До вибору NAS варто підходити навіть ретельніше, ніж до DAS-пристроїв, адже таке обладнання може не підтримувати необхідні вам сервіси, наприклад, Encrypting File Systems (EFS) від Microsoft і IPSec. До слова можна помітити, що NAS поширені набагато менше, ніж пристрої SAN, але відсоток таких систем все ж постійно, хоча і повільно, зростає - в основному за рахунок витіснення DAS.
Пристрої для підключення в SAN (Storage Area Network)- пристрої для підключення в мережу зберігання даних. Мережа зберігання даних (SAN) не коштує плутати з локальною мережею - це різні мережі. Найчастіше SAN грунтується на стекупротоколів FibreChannel і в найпростішому випадку складається з СГД, комутаторів і серверів, об'єднаних оптичними каналами зв'язку. На малюнку ми бачимо високонадійну інфраструктуру, в якій сервери включені одночасно в локальну мережу (ліворуч) і в мережу зберігання даних (праворуч):
images \ RAID \ 14.gif
Після досить детального розгляду пристроїв і принципів їх функціонування нам буде досить легко зрозуміти топологію SAN. На малюнку ми бачимо єдину для всієї інфраструктури СГД, до якої підключені два сервера. Сервери мають резервовані шляху доступу - в кожному встановлено по два HBA (або один двухпортовий, що знижує відмовостійкість). Пристрій зберігання має 4 порти, якими воно підключено в 2 комутатора. Припускаючи, що всередині є два резервних процесорних модуля, легко здогадатися, що найкраща схема підключення - коли кожен комутатор підключений і в перший, і в другий процесорний модуль. Така схема забезпечує доступ до будь-яких даних, що знаходяться на СГД, при виході з ладу будь-якого процесорного модуля, комутатора або шляху доступу. Надійність СГД нами вже вивчена, два комутатора і дві фабрики ще більш збільшують доступність топології, так що якщо через збій або помилки адміністратора один з комутаційних блоків раптом відмовив, другий буде функціонувати нормально, адже ці два пристрої не пов'язані між собою.
Показане підключення серверів називається підключенням з високою доступністю (high availability), хоча в сервері при необхідності може бути встановлено ще більше число HBA. Фізично кожен сервер має тільки два підключення в SAN, проте логічно система зберігання доступна через чотири шляхи - кожна HBA надає доступ до двох точках підключення на СГД, до кожного процесорного модуля окремо (цю можливість забезпечує подвійне підключення комутатора до СГД). На даній схемі саме ненадійною пристрій - це сервер. Два комутатора забезпечують надійність порядку 99,99%, а ось сервер може відмовити з різних причин. Якщо необхідна високонадійних робота всієї системи, сервери об'єднуються в кластер, наведена схема не вимагає ніякого апаратного доповнення для організації такої роботи і вважається еталонною схемою організації SAN. Найпростіший же випадок - сервери, підключені єдиним шляхом через один світч до системи зберігання. Однак система зберігання при наявності двох процесорних модулів повинна підключатися в комутатор як мінімум одним каналом на кожен модуль - інші порти можуть бути використані для прямого підключення серверів до СГД, що іноді необхідно. І не варто забувати, що SAN можливо побудувати не тільки на базі FibreChannel, але і на базі протоколу iSCSI - при цьому можна використовувати тільки стандартні ethernet-пристрої для комутації, що здешевлює систему, але має ряд додаткових мінусів (обумовлених в розділі, який розглядає iSCSI ). Також цікава можливість завантаження серверів з системи зберігання - не обов'язково навіть наявність внутрішніх жорстких дисків в сервері. Таким чином, з серверів остаточно знімається задача зберігання будь-яких даних. В теорії спеціалізований сервер може бути перетворений в звичайну чіслодробілку без будь-яких накопичувачів, що визначають блоками якого є центральні процесори, пам'ять, а так само інтерфейси взаємодії із зовнішнім світом, наприклад порти Ethernet і FibreChannel. Якась подоба таких пристроїв являють собою сучасні blade-сервери.
Хочеться відзначити, що пристрої, які можна підключити в SAN, не обмежені тільки дисковими СГД - це можуть бути дискові бібліотеки, стрічкові бібліотеки (стримери), пристрої для зберігання даних на оптичних дисках (CD / DVD та інші) і багато інших.
З мінусів SAN відзначимо лише високу вартість її компонент, однак плюси незаперечні:
* Висока надійність доступу до даних, що знаходяться на зовнішніх системахзберігання. Незалежність топології SAN від використовуваних СГД і серверів.
* Централізоване зберігання даних (надійність, безпеку).
* Зручне централізоване управління комутацією і даними.
* Перенесення інтенсивного трафіку введення-виведення в окрему мережу, розвантажуючи LAN.
* Висока швидкодія та низька латентність.
* Масштабованість і гнучкість логічної структури SAN
* Географічно розміри SAN, на відміну від класичних DAS, практично не обмежені.
* Можливість оперативно розподіляти ресурси між серверами.
* Можливість будувати відмовостійкі кластерні рішення без додаткових витрат на базі наявної SAN.
* проста схемарезервного копіювання - всі дані знаходяться в одному місці.
* Наявність додаткових можливостей і сервісів (снапшоти, віддалена реплікація).
* Високий ступінь безпеки SAN.
На закінчення
Думаю, ми досить повно висвітлили основне коло питань, пов'язаних з сучасними системами зберігання. Будемо сподіватися, що такі пристрої будуть ще стрімкіше розвиватися функціонально, а число механізмів управління даними буде тільки рости.
На закінчення можна сказати, що NAS і SAN-рішення в даний момент переживають справжній бум. Число виробників і різноманітність рішень збільшується, технічна грамотність споживачів зростає. Сміливо можна припускати, що в найближчому майбутньому практично в кожній обчислювальної середовищі з'являться ті чи інші системи зберігання даних.
Будь-які дані постають перед нами у вигляді інформації. Сенс роботи будь-яких обчислювальних пристроїв - обробка інформації. Останнім часом обсяги її зростання часом лякають, тому системи зберігання даних і спеціалізоване програмне забезпечення, безсумнівно, будуть самим затребуваними продуктами IT-рику в найближчі роки.
Мережеві сховища даних NAS
Обсяги інформації та даних, з якими працюють сучасні компанії, значно перевищують рівень десятирічної і навіть п'ятирічної давності. Технічні рішення, що дозволяють сьогодні оперативно обробляти такі масштаби корпоративних даних істотно відрізняються від схем, що працюють в умовах "побутового користування". Для життєдіяльності бізнесу необхідні вже кілька серверів, що одночасно виконують різні завдання: термінальні, поштові, DNS, проксі-сервери і інші, часто вже не об'єднані в кластерну систему. При такому розподілі виникає проблема оперативної обробки і резервування даних з різних пристроїв. Для вирішення цього завдання використовуються системи зберігання даних (СЗД), вибрати і купити які пропонує наша компанія.
Переваги використання зовнішнього мережевого сховища даних
Подібна система зберігання даних (СЗД) для роботи з даними є комплексним рішенням, що дозволяє централізовано зберігати будь-які обсяги інформації, забезпечуючи надійність її захисту, оперативність обробки та повне архівування. Мережеве сховище даних має ще кілька переваг перед класичними рішеннями розподілу інформації між декількома серверами. Відмовостійкість досягається можливістю як часткового, так і повного резервування складових мережевий СГД. Зовнішнє Мережеве сховищеданих відрізняється більш потужної продуктивністю і оперативністю передачі даних, легко адаптується під бізнес-потреби компанії, так як має можливість легко масштабироваться і підлаштовуватися під зміни обсягу інформаційних потоків даних в компанії. Сховище даних на відміну від стандартних баз даних можна використовувати не тільки для обробки транзакцій, а й для аналізу динаміки продажів за декілька років, формування звітів в різних форматах, інтегрування даних з різних реєструючих систем.
Існує чотири види зберігання даних:
- NAS. Надійні, недорогі і легко настроюються комплекси.
- DAS. Схеми з зовнішньої магістраллю, що дає можливість підключення необмеженої кількості дисків.
- SAN. Добре підходять для зберігання поштової бази даних і забезпечують оперативний доступ до інформації.
- Відмовостійкі сховища даних. Об'єднуються в кластерну схему і забезпечують найбільшу надійність і швидкість передачі даних.
Зовнішні сховища даних застосовуються з метою економії внутрішнього дискового простору, запобігання втрати даних, забезпечення безпеки та доступності вмісту в будь-який час.
Купити мережеве сховище даних за хорошу вартість? Вам сюди!
Якщо ви вирішили купити мережеве сховище даних для своєї організації, компанія Трініті забезпечить Ваш бізнес надійними і потужними системами зберігання даних. У нашому асортименті є різні конфігурації СГД. Ми є офіційними представниками лідируючих на світовому ринку виробників IT-обладнання та маємо можливість оперативно укомплектувати сховище даних будь-якої конфігурації. Ми пропонуємо системи зберігання даних від таких виробників як Dell, HP, Lenovo, EMC і ін.
Для кожної конкретної компанії в залежності її вимог і завдань, наші фахівці допоможуть вибрати або зібрати систему зберігання даних в індивідуальній комплектації, оптимальної для її масштабів, бюджету та вже працює мережевої інфраструктури. Ціна на обрану систему зберігання даних буде залежати від комплектації, вартість проектування сховища даних в залежності від поставлених завдань, ви можете уточнити у наших фахівців.
Всі роботи з аналізу поточного стану технічної бази, підбору потрібної комплектації і установці обладнання наша компанія бере на себе. Вам необхідно просто залишити заявку нашим фахівцям.
Крім того, ми забезпечуємо технічну підтримкуобладнання, що постачається. Наші співробітники - це висококваліфіковані інженери, монтажники, IT-фахівці нададуть Вам кваліфіковану допомогу в будь-який час. Від професійної консультації до модернізації і розробки обладнання.
Яким чином потрібно класифікувати архітектурні схеми СГД? Мені здається, актуальність цього питання в подальшому буде тільки рости. Як розібратися у всьому цьому різноманітті пропозицій, наявних на ринку? Відразу хочу попередити, що цей пост не призначений для ледачих або не бажають багато читати.
Можна цілком успішно класифікувати системи зберігання, на зразок того, як біологи вибудовують родинні зв'язки між видами живих організмів. Якщо хочете, можна назвати це «древом життя» світу технологій зберігання інформації.
Побудова подібних древ допомагає краще розуміти навколишній світ. Зокрема, можна вибудувати схему походження і розвитку будь-яких видів СГД, і швидко зрозуміти, що ж лежить в основі будь-якої нової технології, що з'являється на ринку. Це дозволяє відразу визначити сильні і слабкі сторони того чи іншого рішення.
Сховища, що дозволяють працювати з інформацією будь-якого виду, архітектурно можна розділити на 4 основні групи. Головне, не зациклюватися на деяких речах, які збивають з пантелику. Багато схильні класифікувати платформи на основі таких «фізичних» критеріїв, як межкомпонентное з'єднання (interconnect) ( «У них у всіх є внутрішня шина між нодамі!»), Або протокол ( «Це блок, або NAS, або багатопротокольна система!»), або ділять на апаратні і програмні ( «Це ж просто ПО на сервері!»).
це абсолютно неправильний підхіддо класифікування. Єдино вірним критерієм є програмна архітектура, яка використовується в тому чи іншому рішенні, оскільки від цього залежать всі основні характеристики системи. Інші компоненти СГД залежать від того, яка саме програмна архітектура була обрана розробниками. І з цієї точки зору «апаратні» і «програмні» системи можуть бути лише варіаціями тієї чи іншої архітектури.
Але не зрозумійте мене неправильно, я не хочу сказати, що різниця між ними невелика. Просто вона не фундаментальна.
І хочу ще дещо уточнити, перш ніж перейти до справи. Для нашої натури властиво ставити запитання «А що з цього найкраще / правильне?». Відповісти на це можна тільки одне: «Є кращі рішеннядля якихось конкретних ситуацій або видів навантаження, але не існує універсального ідеального рішення ». Саме особливості навантаження диктують вибір архітектури, І більше ніщо інше.
До слова, нещодавно я брав участь в забавній бесіді на тему ЦОД, які працюють виключно на флеш-накопичувачах. Мені імпонує пристрасність в будь-яких проявах, і цілком очевидно, що флеш поза конкуренцією в ситуаціях, коли продуктивність і час затримки відіграють вирішальну роль (крім багатьох інших чинників). Але мушу визнати, що мої співрозмовники були неправі. У нас є один клієнт, його послугами, навіть не підозрюючи про це, щодня користується безліч людей. Чи може він повністю перейти на флеш? Ні.

Це великий клієнт. А ось інший, ВЕЛИЧЕЗНИЙ, раз в 10 більше. І я знову не можу погодитися з тим, що цей клієнт може перейти виключно на флеш:
Зазвичай як контраргумент заявляють, що в кінці кінців флеш досягне такого рівня розвитку, що затьмарить магнітні накопичувачі. Із застереженням, що флеш буде застосовуватися з парі з Дедуплікація. Але не у всіх випадках доцільно застосовувати Дедуплікація, як і компресію.
Ну, з одного боку, флеш-пам'ять буде дешевшати, до певної межі. Мені здавалося, що це буде відбуватися трохи швидше, але вже доступні SSD-накопичувачі ємністю 1 Тб за $ 550, це великий прогрес. Звичайно, розробники традиційних вінчестерів теж не сидять склавши руки. В районі 2017-2018 років конкуренція повинна посилитися, оскільки будуть впроваджуватися нові технології (найімовірніше, фазовий зсув і вуглецеві нанотрубки). Але справа зовсім не в протистоянні флеш і вінчестерів, або навіть програмних і апаратних рішень, головне - архітектура.
Вона настільки важлива, що практично неможливо поміняти архітектуру СГД, які не переробивши практично все. Тобто, по суті, не створивши нову систему. Тому сховища зазвичай створюються, розвиваються і вмирають в рамках якоїсь однієї спочатку обраної архітектури.
Чотири типу систем зберігання даних
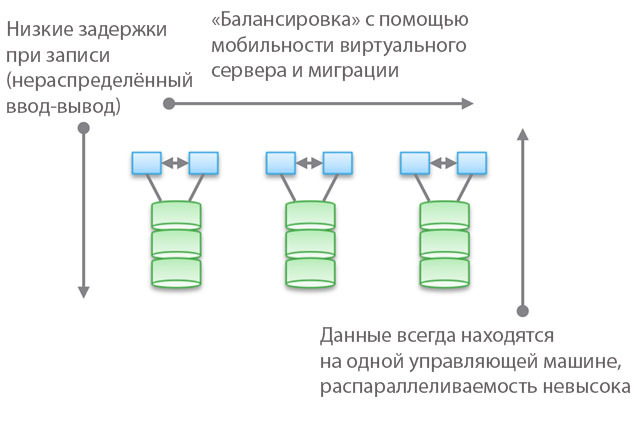
Тип 1. Групові архітектури. Вони не розраховані на спільне використанняпам'яті нодамі, по суті, всі дані знаходяться в одному ноді. Однією з особливостей архітектури є те, що іноді пристрою «перетинаються» (trespass), навіть якщо вони «доступні з декількох нодов». Інша особливість полягає в тому, що ви можете вибрати машину, вказати їй якісь накопичувачі і сказати «ця машина має доступ до даних на цих носіях». Синім на малюнку позначені ЦПУ / пам'ять / система введення-виведення, а зеленим - носії, на яких зберігаються дані (флеш або магнітні накопичувачі).
Для даного типу архітектур характерний прямий і дуже швидкий доступ до даних. Між машинами будуть виникати невеликі затримки, оскільки для забезпечення високої доступності застосовується віддзеркалення введення-виведення і кешування. Але в цілому забезпечується щодо прямий доступ по гілці коду. Програмні сховища досить прості і мають малий час затримки, тому часто володіють багатим функціоналом, служби даних легко додаються. Не дивно, що більшість стартапів починають з подібних сховищ.
Зверніть увагу, що однією з різновидів цього типу архітектур є PCIe-обладнання для НЕ HA-серверів (карти розширення Fusion-IO, XtremeCache). Якщо додати до нього ПО для розподіленого сховища, когерентність і HA-модель, то подібне програмне сховище буде відповідати одному з чотирьох типів архітектур, описуваних в цьому пості.
Застосування «федеративних моделей» допомагає поліпшити горизонтальну масштабованість архітектур цього типу з точки зору менеджменту. У даних моделях можуть використовуватися різні підходи до підвищення мобільності даних для перебалансування між керуючими машинами і сховищами. Наприклад, в рамках VNX це означає «мобільність VDM». Але я вважаю, що називати це «горизонтально масштабується архітектурою» буде натяжкою. І, по моєму досвіду, більшість клієнтів поділяють цю точку зору. Причиною тому розташування даних на одній керуючої машині, іноді - «в апаратній шафі» (behind an enclosure). Їх можна переміщати, але вони завжди будуть в якомусь одному місці. З одного боку, це дозволяє знизити кількість циклів і затримку при записі. З іншого боку, всі ваші дані обслуговуються єдиною керуючою машиною (можливий непрямий доступ з іншої машини). На відміну від другого і третього типів архітектур, про які поговоримо нижче, тут балансування та налаштування грають важливу роль.
Об'єктивно кажучи, цей абстрактний федеративний рівень тягне за собою і деяке збільшення затримки, оскільки використовує програмне перенаправлення. Це аналогічно ускладнення коду і збільшення затримки в типах архітектур 2 і 3, і частково нівелює переваги першого типу. Як конкретний приклад можна привести UCS Invicta, такий собі «Silicon Storage Routers». У випадку з NetApp FAS 8.x, які працюють в кластерному режимі, код неабияк ускладнений впровадженням федеративної моделі.
Продукти, які використовують кластерні архітектури - VNX або NetApp FAS, Pure, Tintri, Nimble, Nexenta і (я думаю) UCS Invicta / UCS. Одні представляють собою «апаратні» рішення, інші - «чисто програмні», треті - «програмні у вигляді апаратних комплексів». Всі вони ДУЖЕ сильно розрізняються з точки зору обробки даних (в Pure і UCS Invicta / Whiptail мається на увазі використання тільки флеш-накопичувачів). Але архітектурно всі перераховані продукти споріднені. Наприклад, ви налаштовуєте служби обробки даних виключно для резервного копіювання, програмний стек стає Data Domain, ваш NAS працює як кращий в світі інструмент для бекапа - і це теж архітектура «першого типу».
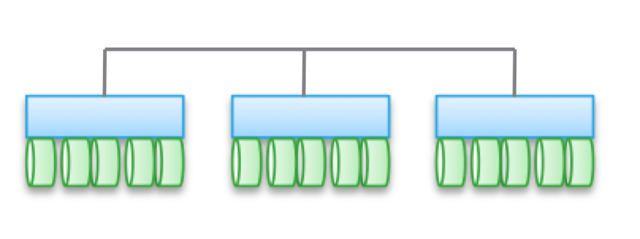
Тип 2. Слабо зв'язані, горизонтально масштабовані архітектури. Ноди не використовують пам'ять спільно, але самі дані по декільком Нодаме. Ця архітектура має на увазі використання більшої кількості межнодових зв'язків для запису даних, що збільшує кількість циклів. Хоч операції записи і розподілені, але завжди когерентні.
Зверніть увагу, що в різні архітектури не забезпечується висока доступність нода в зв'язку з операціями копіювання та розподілу даних. З тієї ж причини тут завжди більше операцій введення-виведення в порівнянні з простими кластерними архітектурою. Так що продуктивність виходить трохи нижче, незважаючи на невеликий рівень затримки при записі (NVRAM, SSD і т.д.).
У деяких різновидах архітектур часто нодов збираються в підгрупи, а решта використовуються для управління підгрупами (ноди метаданих). Але тут проявляються ефекти, описані вище для «федеративних моделей».
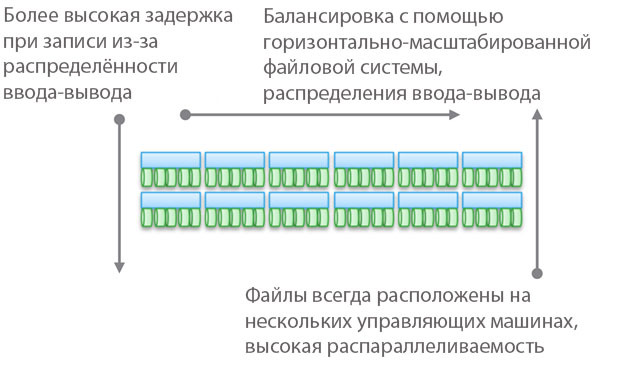
Подібні архітектури досить просто масштабируются. Оскільки дані зберігаються в кількох місцях і можуть оброблятися численними нодамі, ці архітектури можуть відмінно підійти для задач, коли потрібно розподілене читання. Крім того, вони добре поєднуються з ПО для серверів / сховищ. Але найкраще застосовувати подібні архітектури в умовах транзакційних навантажень: завдяки їх розподіленості ви можете не використовувати HA-сервер, а слабка спряженість дозволяє обійтися Ethernet.
Цей тип архітектур використовується в таких продуктах, як EMC ScaleIO і Isilon, VSAN, Nutanix і Simplivity. Як у випадку з Типом 1, всі ці рішення абсолютно несхожі один на одного.
Слабка спряженість означає, що найчастіше ці архітектури дозволяють помітно збільшувати кількість нодов. Але, нагадаю, вони НЕ використовують пам'ять спільно, код кожного нода працює незалежно від інших. Але диявол, як то кажуть, в деталях:
- Чим більше розподілені операції записи, тим вище затримки і нижче ефективність IOP. Наприклад, в Isilon рівень розподіленості дуже високий файлів, і хоча з кожним оновленням затримки зменшуються, але все ж він ніколи не продемонструє високої продуктивності. Зате Isilon надзвичайно сильний з точки зору распаралеллеліванія.
- Якщо зменшити ступінь розподіленості (нехай і при великій кількості нодов), то затримки можуть знизитися, але при цьому ви уріже свої можливості по распараллеливанию читання даних. Наприклад, у VSAN використовується модель «віртуальна машина як об'єкт», що дозволяє запускати численні копії. Здавалося б, віртуальна машина повинна бути доступна певного хосту. Але, по факту, під VSAN вона «зсувається» у напрямку до ноду, який зберігає її дані. Якщо ви використовуєте це рішення, то можете самі подивитися, як збільшення кількості копій об'єкта впливає на затримку і операції введення-виведення в рамках всієї системи. Підказка: більше копій = вище навантаження на систему в цілому, причому залежність нелінійна, як ви могли б очікувати. Але для VSAN це не проблема завдяки перевагам моделі «віртуальна машина як об'єкт».
- Можна домогтися низької затримки в умовах високого масштабування і розпаралелювання при читанні, але тільки за умови точного поділу даних і запису невеликої кількості копій. Цей підхід використовується в ScaleIO. Кожен том розділений на велику кількість фрагментів (за замовчуванням по 1 Мб), які розподілені по всім задіяним Нодаме. В результаті досягається надзвичайно висока швидкість читання і перерозподілу поряд з потужним розпаралелюванням. Затримка при запису може бути менше 1 мсек при використанні відповідної мережевої інфраструктури і SSD / PCIe Flash в нодах кластера. Однак кожна операція запису провадиться в двох нодах. Звичайно, на відміну від VSAN тут віртуальна машина не розглядається як об'єкт. Але якби розглядалася, то масштабованість була б гірше.
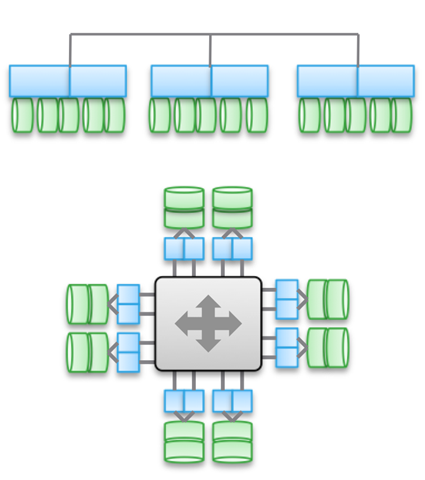
Тип 3. Сильно зв'язані, горизонтально масштабовані архітектури. Тут застосовується спільне використання пам'яті (для кешування і деяких типів метаданих). Дані розподілені по різним Нодаме. Цей тип архітектур на увазі використання дуже великої кількості межнодових з'єднань для всіх видів операцій.
Спільне використання пам'яті є наріжним каменем цих архітектур. Історично склалося, що через всі керуючі машини можуть здійснюватися симетричні операції введення-виведення (див. Ілюстрацію). Це дозволяє перебалансувати навантаження в разі виникнення будь-яких збоїв. Дана ідея закладалася в основу таких продуктів, як Symmetrix, IBM DS, HDS USP і VSP. У них здійснюється сумісні доступ до кешу, тому процедура введення-виведення можна керувати за будь-якої машини.
Верхня діаграма на ілюстрації відображає архітектуру EMC XtremIO. На перший погляд, вона аналогічна Типу 2, але це не так. В даному випадкумодель спільно використовуваних розподілених метаданих має на увазі використання IB і віддаленого прямого доступу до пам'яті, щоб всі ноди мали доступ до метаданих. При цьому кожен нод є HA-пару. Як бачите, Isilon і XtremIO сильно розрізняються архітектурно, хоча це і не так очевидно. Так, у обох горизонтально масштабовані архітектури, в обох для межкомпонентное з'єднання використовується IB. Але в Isilon, на відміну від XtremIO, це робиться для максимального зниження затримки при обміні даними між нодамі. Також в Isilon для зв'язку між нодамі можна використовувати Ethernet (фактично, саме так на ньому працює віртуальна машина), але це збільшує затримки при операціях введення-виведення. Що стосується XtremIO, то для його продуктивності велике значення має віддалений прямий доступ до пам'яті.
До речі, нехай вас не вводить в оману наявність двох діаграм на ілюстрації - насправді, архітектурно вони однакові. В обох випадках використовуються пари HA-контролерів, спільний доступ до пам'яті і міжкомпонентні з'єднання з дуже низьким рівнем затримки. До речі, в VMAX використовується пропріетарна межкомпонентное шина, але в майбутньому з'явиться можливість застосування IB.
Для сильно сполучених архітектур характерна висока складність програмного коду. Це одна з причин їх невисокою поширеності. Зайва складність ПО впливає і на кількість додаються служб обробки даних, оскільки це є більш важку обчислювальну задачу.
До переваг цього типу архітектур можна віднести стійкість до збоїв (симетричні операції введення-виведення в усіх керуючих машинах), а також, у випадку з XtremIO, великі можливості в сфері AFA. Раз мова знову зайшла про XtremIO, то варто згадати, що його архітектура має на увазі розподіленість всіх служб обробки даних. Також це єдине на ринку AFA-рішення з горизонтально масштабированной архітектурою, хоча динамічне додавання / відключення нодов ще не впроваджено. Крім іншого, в XtremIO використовується «природна» дедуплікація, тобто вона постійно активна і «безкоштовна» з точки зору продуктивності. Правда, все це підвищує складність обслуговування системи.
Важливо розуміти принципову різницю між Типом 2 і Типом 3. Чим більше сполучена архітектура, тим краще і більш прогнозовано вона дозволяє забезпечувати низький рівень затримок. З іншого боку, в рамках подібної архітектури складніше додавати Ноди і масштабувати систему. Адже коли ви використовуєте спільний доступ до пам'яті, вона являє собою єдину сильно пов'язану розподілену систему. Складність рішень зростає, а разом з цим і вірогідність помилок. Тому VMAX може мати до 16 керуючих машин в 8 двигунах, а XtemIO - до 8 машин в 4 X-Brick (скоро збільшиться до 16 машин в 8 блоках). Учетвереніе, або навіть подвоєння цих архітектур є неймовірно важку інженерну проблему. Для порівняння, VSAN може бути масштабований до «розміру кластерів vSphere» (зараз 32 нода), Isilon може містити більше 100 нодов, а ScaleIO дозволяє створити систему з більш ніж 1000 нодов. При цьому все це архітектури другого типу.
Знову хочу підкреслити - архітектура не залежить від реалізації. У вищезазначених продуктах використовується і Ethernet, і IB. Одні представляють собою чисто програмні рішення, інші є програмно-апаратними комплексами, але при цьому їх об'єднують архітектурні схеми.
Незважаючи на різноманітність межкомпонентних з'єднань, у всіх наведених прикладах найважливішу роль відіграє використання розподіленої записи. Це дозволяє досягти транзакційності і атомарности, але при цьому необхідний ретельний контроль цілісності даних. Також доводиться вирішувати проблему розростання «області відмов». Ці два моменти обмежують максимально можливу ступінь масштабування описаних типів архітектур.
Невелика перевірка того, наскільки уважно ви прочитали все вищевикладене: До якого типу належить Cisco UCS Invicta - 1 або 3? Фізично виглядає як Тип 3, але ж це набір USC-серверів серії С, з'єднаних по Ethernet, на яких працює програмний стек Invicta (колишній Whiptail). Підказую: дивіться на архітектуру, а не конкретну реалізацію 🙂
У випадку з UCS Invicta дані зберігаються в кожному ноді (UCS-сервер з флеш-накопичувачами на базі MLC). Єдиний нод, що не HA, що представляє собою окремий сервер, може безпосередньо передавати номер логічного пристрою (LUN). Якщо ви вирішите додати ще Ноди, можливо система масштабується слабосопряжённо, як ScaleIO або VSAN. Все це підводить нас до Типу 2.
Однак збільшення кількості нодов, судячи по всьому, проводиться за допомогою конфігурації і міграції на "Invicta Scaling Appliance". При такій конфігурації у вас є кілька "Silicon Storage Routers" (SSR) і адресний сховище з декількох апаратних нодов. Доступ до даних здійснюється через єдиний SSR-нод, але це можна зробити і через інший нод, що працює як HA-пара. Самі дані завжди знаходяться на єдиному UCS-ноді серії С. Так який же це тип архітектури? Не важливо, як виглядає рішення фізично, - це Тип 1. SSR є кластер (може бути більше 2). У конфігурації Scaling Appliance кожен UCS-сервер з MLC-накопичувачами виконує функцію, аналогічну VNX або NetApp FAS - дисковий сховище. Хоч і не підключений через SAS, але архітектура аналогічна.
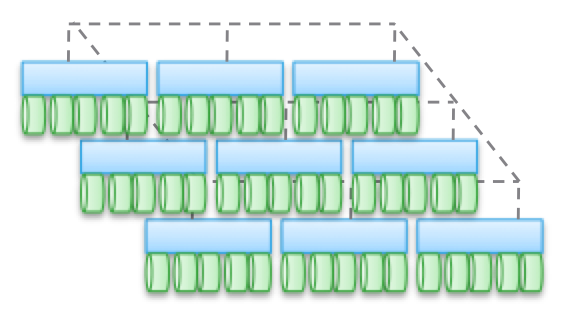
Тип 4. Розподілені архітектури без спільно використання будь-яких ресурсів. Незважаючи на те, що дані розподіляються за різними Нодаме, робиться це без будь-якої транзакційності. Зазвичай дані складуються на якомусь одному ноді і там живуть, і час від часу робляться копії на інших нодах, заради забезпечення безпеки. Але ці копії не транзакційні. це є ключовою відмінністюданого типу архітектур від Типу 2 і 3.
Зв'язок між НЕ-HA-нодамі здійснюється за допомогою Ethernet, оскільки це дешево і універсально. Розподіл по Нодаме робиться примусово і час від часу. «Коректність» даних дотримується не завжди, але програмний стек перевіряється досить часто, щоб забезпечувати правильність використовуваних даних. При деяких видах навантаження (наприклад, HDFS) дані розподіляються так, щоб перебувати в пам'яті одночасно з тим процесом, для якого вони потрібні. Це властивість дозволяє вважати даний типархітектур найбільш масштабованим серед всіх чотирьох.
Але це далеко не єдина перевага. Подібні архітектури надзвичайно прості, ними дуже легко управляти. Вони жодним чином не залежать від устаткування і можуть бути розгорнуті на найдешевшому «залізі». Це майже завжди виключно програмні рішення. Архитектурам цього типу оперувати петабайт даних так само просто, як дргугім - терабайтами. Тут застосовуються об'єкти і неPOSIX-файлові системи, причому і ті, й інші часто розташовуються поверх локальної файлової системи кожного рядового нода.
Ці архітектури можна поєднувати з блоками і транзакційними моделями представлення даних на базі NAS, але це сильно обмежує їх можливості. Не треба створювати транзакційний стек, поміщаючи Тип 1, 2 або 3 поверх Типу 4.
Найкраще ці архітектури «розкриваються» на тих завданнях, для яких не властиві якісь обмеження.
Вище я наводив приклад з дуже великим клієнтом, у якого 200 000 накопичувачів. В основі таких сервісів, як Dropbox, Syncplicity, iCloud, Facebook, eBay, YouTube і майже всіх Web 2.0-проектів лежать сховища, побудовані по архитектурам четвертого типу. Вся оброблювана інформація в Hadoop-кластерах також міститься в сховищах на базі Типу 4. В цілому, в корпоративному сегменті це не дуже поширені архітектури, але вони дуже швидко завойовують популярність.
Тип 4 лежить в основі таких продуктів, як AWS S3 (до речі, ніхто за межами AWS не знає, як влаштований EBS, але готовий сперечатися, що це тип 3), Haystack (використовується в Facebook), Atmos, ViPR, Ceph, Swift ( використовується в Openstack), HDFS, Centera. Багато хто з перерахованих продуктів можуть набувати різну форму, вид конкретної реалізації визначається за допомогою їх API. Наприклад, об'єктний стек ViPR можна реалізувати через об'єктні API S3, Swift, Atmos, і навіть HDFS! А в майбутньому в цей список потрапить і Centera. Для кого-то це буде очевидно, але Atmos і Centera будуть використовуватися ще довго, правда, у вигляді API, а не конкретних продуктів. Реалізації можуть змінюватися, але API залишаються чимось непорушним, що дуже добре для клієнтів.
Хочу ще раз звернути вашу увагу на те, що «фізичне втілення» може збити вас з пантелику, і архітектури Типу 4 ви помилково віднесете до Типу 2, оскільки вони, найчастіше, виглядають однаково. На фізичному рівні якесь від рішення може виглядати як ScaleIO, VSAN або Nutanix, хоча це будуть просто сервери з Ethernet. І правильно класифікувати те чи інше рішення допоможе наявність або відсутність транзакційності.
А тепер я пропоную вам другий перевірки тест. Давайте розглянемо архітектуру UCS Invicta. Фізично цей продукт виглядає як Тип 4 (сервери, з'єднані по Ethernet), але архітектурно його неможливо масштабувати під відповідні навантаження, оскільки насправді це Тип 1. Причому Invicta, як і Pure, розроблявся для AFA.
Прийміть мою щиру подяку за приділеною час і увагу, якщо ви дочитали до цього місця. Перечитав написане вище - дивно, що мені вдалося одружитися і завести дітей 🙂
Для чого я все це розписав?
У світі IT сховища займають дуже важливе місце, отаке «царство грибів». Різноманітність пропонованих продуктів дуже велике, і це йде тільки на користь всій справі. Але потрібно вміти розбиратися у всьому цьому, не дозволяти затуманити собі розум маркетинговими слоганами і нюансами позиціонування. Заради блага як клієнтів, так і самої індустрії, необхідно спростити процес побудови сховищ. Тому ми докладаємо стільки зусиль, щоб зробити з контролера ViPR відкриту безкоштовну платформу.
Але самі по собі сховища важко назвати захоплюючими. Що я маю на увазі? Уявімо якусь абстрактну піраміду, на вершині якої знаходиться «користувач». Нижче розташовані «додатки», призначені для обслуговування «користувача». Ще нижче - «інфраструктура» (включаючи SDDC), яка обслуговує «додатки» і, відповідно, «користувача». А в самому низу «інфраструктури» знаходиться сховище.
Тобто можна уявити ієрархію в такому вигляді: Пользователь-> Додаток / SaaS-> PaaS-> IaaS-> Інфраструктура. Так ось: в кінці кінців, будь-який додаток, будь PaaS-стек повинні обчислювати або обробляти якусь інформацію. І ці чотири типи архітектур призначені для роботи з різними типамиінформації, різними видами навантаження. В ієрархії важливості інформація йде відразу за користувачем. Мета існування програми полягає в тому, щоб дати користувачеві можливість взаємодіяти з потрібною йому інформацією. Саме тому архітектури систем зберігання даних мають настільки важливе значення в нашому світі.
Запись опубликована автором в рубриці Без рубрики. Додайте в закладки.Система зберігання даних (СЗД)- це конгломерат спеціалізованого обладнання та програмного забезпечення, який призначений для зберігання і передачі великих масивів інформації. Дозволяє організувати зберігання інформації на дискових майданчиках з оптимальним розподілом ресурсів.
Ще один фактор - поява на ринку безлічі компаній, які пропонують свої рішення для підтримки бізнесу підприємств: ERP, біллінгові системи, системи підтримки прийняття рішень і т. Д. Всі вони дозволяють збирати детальні дані самого різного характеру у величезних обсягах. При наявності в організації розвиненою ІТ-інфраструктури ці дані можна зібрати разом і проаналізувати їх.
Наступний фактор - технологічного характеру. До деякого часу виробники додатків самостійно розробляли різні версії своїх рішень для різних серверних платформ або пропонували відкриті рішення. Важливою для галузі технологічної тенденцією стало створення адаптуються платформ для вирішення різних аналітичних завдань, які включають апаратну складову і СУБД. Користувачів вже не хвилює, хто зробив для їх комп'ютера процесор або оперативну пам'ять, - вони розглядають сховище даних як якусь послугу. І це найважливіший зрушення в свідомості.
Технології, які дозволяють використовувати сховища даних для оптимізації операційних бізнес-процесів практично в реальному часі не тільки для висококваліфікованих аналітиків і топ-менеджерів, а й для співробітників фронт-офісу, зокрема для співробітників офісів продажів і сервісних центрів. Прийняття рішень делегується співробітникам, що стоять на нижчих щаблях корпоративних сходів. Необхідні їм звіти, як правило, прості і короткі, але їх потрібно дуже багато, а час формування повинно бути невелика.
Сфери застосування СГД
Традиційні сховища даних можна зустріти повсюдно. Вони призначені для формування звітності, що допомагає розібратися з тим, що сталося в компанії. Однак це перший крок, базис.
Людям стає недостатньо знати, що сталося, їм хочеться зрозуміти, чому це сталося. Для цього використовуються інструменти бізнес-аналітики, які допомагають зрозуміти те, що говорять дані.
Слідом за цим приходить використання минулого для передбачення майбутнього, побудова прогностичних моделей: які клієнти залишаться, а які підуть; які продукти чекає успіх, а які виявляться невдалими і т.д.
Деякі організації вже знаходяться на стадії, коли сховища даних починають використовувати для розуміння того, що відбувається в бізнесі в теперешній час. Тому наступний крок - це «активація» фронтальних систем за допомогою рішень, заснованих на аналізі даних, найчастіше в автоматичному режимі.
Обсяги цифрової інформації ростуть лавиноподібно. У корпоративному секторі цей підйом був викликаний, з одного боку, посиленням регулювання і вимогою зберігати все більше інформації, що відноситься до ведення бізнесу. З іншого боку, посилення конкуренції вимагає все більш точної і докладної інформації про ринок, клієнтів, їх перевагах, замовленнях, діях конкурентів і т.д.
У державному секторі зростання обсягів збережених даних підтримує повсюдний перехід до міжвідомчого електронного документообігу та створення відомчих аналітичних ресурсів, основою яких є різноманітні первинні дані.
Не менш потужну хвилю створюють і звичайні користувачі, Які викладають в інтернет свої фотографії, відеоролики і активно обмінюються мультимедійним контентом в соціальних мережах.
Вимоги до СГД
Який критерій вибору дискових СГД для Вас важливіше? Результат опитування на сайті www.timcompany.ru, лютий 2012 року
Група компаній ТІМ в 2008 році провела опитування серед клієнтів з метою з'ясувати, які характеристики найбільш важливі для них при виборі СГД. На перших позиціях опинилися якість і функціональність пропонованого рішення. У той же час розрахунок сукупної вартості володіння для російського споживача явище нетипове. Замовники найчастіше не до кінця усвідомлюють які їх очікують витрати, наприклад, витрати на оренду і оснащення приміщення, електроенергію, кондиціювання, навчання і зарплату кваліфікованого персоналу і ін.
Коли виникає необхідність придбати СГД, максимум, що оцінює для себе покупець, це прямі витрати, що проходять через бухгалтерію на придбання даного обладнання. Втім, ціна за ступенем важливості виявилася на дев'ятому місці з десяти. Безумовно, замовники враховують можливі труднощі, пов'язані з обслуговуванням техніки. Зазвичай їх уникнути допомагають пакети розширеної гарантійної підтримки, які зазвичай пропонують в проектах.
Надійність і відмовостійкість.У СГД передбачено повне або часткове резервування всіх компонент - блоків живлення, шляхів доступу, процесорних модулів, дисків, кеша і т.д. Обов'язкова наявність системи моніторингу та оповіщення про можливі і існуючі проблеми.
Доступність даних.Забезпечується продуманими функціями збереження цілісності даних (використання технології RAID, створення повних і миттєвих копій даних усередині дискової стійки, реплицирования даних на віддалену СГД і т.д.) і можливістю додавання (поновлення) апаратури і програмного забезпеченняв гарячому режимі без зупинки комплексу;
Засоби управління і контролю.Управління СГД здійснюється через web-інтерфейс або командний рядок, Є функції моніторингу і кілька варіантів оповіщення адміністратора про неполадки. Доступні апаратні технології діагностики продуктивності.
Продуктивність.Визначається числом і типом накопичувачів, об'ємом кеш-пам'яті, обчислювальною потужністю процессорной підсистеми, числом і типом внутрішніх і зовнішніх інтерфейсів, а також можливостями гнучкої настройки і конфігурації.
Масштабованість.У СГД зазвичай присутня можливість нарощування числа жорстких дисків, об'єму кеш-пам'яті, апаратної модернізації і розширення функціоналу за допомогою спеціального програмного забезпечення. Всі перераховані операції виробляють без значного переконфігуруванні і втрат функціональності, що дозволяє економити і гнучко підходити до проектування ІТ-інфраструктури.
типи СГД
дискові СГД
Використовують для оперативної роботи з даними, а також для створення проміжних резервних копій.
Існують наступні види дискових СГД:
- СГД для робочих даних (високопродуктивне обладнання);
- СГД для резервних копій (дискові бібліотеки);
- СГД для довготривалого зберіганняархівів (системи CAS).
стрічкові СГД
Призначені для створення резервних копій і архівів.
Існують наступні види стрічкових СГД:
- окремі накопичувачі;
- Автозавантажувач (один накопичувач і кілька слотів для стрічок);
- стрічкові бібліотеки (більше одного накопичувача, безліч слотів для стрічок).
Варіанти підключень СГД
Для підключення пристроїв і жорстких дисківвсередині одного сховища використовуються різні внутрішні інтерфейси:
Найбільш поширені зовнішні інтерфейси підключення СГД:
Популярний інтерфейс межузлового кластерного взаємодії Infiniband тепер також використовується для доступу до СГД.
Варіанти топологій СГД
Традиційний підхід до сховищ даних складається в безпосередньому підключенні серверів до системи зберігання Direct Attached Storage, DAS (Direct Attached Storage). Крім Direct Attached Storage, DAS, існують пристрої зберігання даних, що підключаються до мережі, - NAS (Network Attached Storage), a також компоненти мереж зберігання даних - SAN (Storage Area Networks). І NAS -, і SAN-системи з'явилися в якості альтернативи архітектурі Direct Attached Storage, DAS. Причому кожне рішення розроблялося як відповідь на зростаючі вимоги до систем зберігання даних і грунтувалося на використанні доступних у той час технологіях.
архітектури мережевих системзберігання були розроблені в 1990-х рр., і їх завданням було усунення основних недоліків систем Direct Attached Storage, DAS. У загальному випадку мережеві рішенняв області систем зберігання повинні були реалізувати три завдання: знизити витрати і складність управління даними, зменшити трафік локальних мереж, Підвищити ступінь готовності даних і загальну продуктивність. При цьому архітектури NAS і SAN вирішують різні аспекти загальної проблеми. Результатом стало одночасне співіснування двох мережевих архітектур, кожна з яких має свої переваги і функціональні можливості.
Системи зберігання прямого підключення (DAS)
Оскільки СГД невіддільні від обчислювальних ресурсів, то не дивно, що багато найбільші світові виробники систем зберігання є одночасно і лідерами на серверному ринку. З перерахованих вище виробників тільки три займаються виключно СГД - це EMC, Hitachi і NetApp.
З виробників СГД, представлених в нашій країні, відзначимо компанії, які відносяться до згаданого вище класу «Б».
- Cisco (Linksys)
Набирає популярність концепція публічних хмар впливає на сегмент СГД. Власники публічних хмар менше схильні до виплати бренд-премії, що може відкрити широкі можливості для виробників другого ешелону, нішевих або нових гравців.
Вітчизняні виробники дискових СГД (наприклад, компанія DEPO Computers (ДЕПО Електронікс)) збирають свої системи на базі компонентів зарубіжних виробників, в тому числі Microsemi (раніше Adaptec), Chenbro, Falconstore, Intel, LSI Logic, Lustre та інших. В цілому ж СГД місцевого виробництва поставляються переважно в невеликі проекти. Крім того, важливо відзначити, що в сегменті СГД спостерігається стійка тенденція до витіснення вітчизняних компаній світовими.
Важливою відмінністю систем А-брендів від СГД місцевого виробництва є наявність у них спеціального ПО, призначеного для відновлення і захисту даних, резервного копіювання, віддаленого управлінняі моніторингу, «управління життєвим циклом інформації» (Information Lifecycle Management, ILM), діагностики і т.д. ПО зі схожими функціями розробляє і безліч незалежних компаній, тому його можна придбати окремо. Звичайно, при відсутності проблем з сумісністю.
Вартість СГД дуже сильно залежить від функціональних можливостейі додаткових опцій - модулів розширення, типу жорстких дисків, сервісного обслуговування тощо.
Російський ринок СГД
В останні кілька років російський ринок СГД успішно розвивається і росте. Так, в кінці 2010 року виручка виробників систем зберігання, проданих на російському ринку, перевищила $ 65 млн, що в порівнянні з другим кварталом того ж року більше на 25% і на 59% 2009-го. Загальна ємність проданих СГД склала приблизно 18 тис. Терабайт, що є показником зростання більше ніж на 150% в рік.
Російський ринок систем зберігання даних розвивається надзвичайно динамічно в силу того, що він ще дуже молодий. Відсутність успадкованого обладнання не робить на нього значного впливу, оскільки через вибухового зростання обсягів даних старі системи просто не відповідають вимогам клієнтів і «вимиваються» значно швидше, ніж, наприклад, стародавні сервери і робочі станції.
Стрімке зростання обсягів даних все частіше змушує вітчизняні компанії купувати зовнішні дискові системизберігання. Цьому в чималому ступені сприяє і традиційна тенденція зниження вартості ІТ-компонентів. Якщо раніше зовнішні СГД сприймалися тільки як атрибут великих організацій, то тепер потреба в цих системах немає відкидають навіть невеликі компанії.
Основні етапи проектів створення сховищ даних
Сховище даних - дуже складний об'єкт. Одним з основних умов для його створення є наявність грамотних фахівців, які розуміють, що вони роблять, - не тільки на стороні постачальника, але і на стороні клієнта. Споживання СГД стає невід'ємною частиною впровадження комплексних інфраструктурних рішень. Як правило, мова йде про значні інвестиції на 3-5 років, і замовники розраховують, що протягом всього терміну експлуатації система повною мірою буде відповідати пропонованим з боку бізнесу вимогам.
Далі, необхідно володіти технологіями створення сховищ даних. Якщо ви почали створювати сховище і розробляєте для нього логічну модель, то у вас повинен бути словник, який визначає всі основні поняття. Навіть такі розхожі поняття, як «клієнт» і «продукт», мають сотні визначень. Тільки отримавши уявлення про те, що означають ті чи інші терміни в даній організації, можна визначити джерела необхідних даних, які слід завантажити в сховище.
Тепер можна приступити до створення логічної моделі даних. Це критично важливий етап проекту. Треба від всіх учасників проекту створення сховища даних домогтися згоди щодо актуальності цієї моделі. По завершенні цієї роботи стає зрозуміло, що в дійсності потрібно клієнту. І тільки потім можна буде говорити про технологічні аспекти, наприклад про розміри сховища. Клієнт опиняється віч-на-віч з гігантською моделлю даних, яка містить тисячі атрибутів і зв'язків.
Необхідно постійно пам'ятати, що сховище даних не повинно бути іграшкою для ІТ-департаменту і об'єктом витрат для бізнесу. І в першу чергу сховище даних має допомагати клієнтам вирішувати їх найкритичніші проблеми. Наприклад, допомогти телекомунікаційним компаніям запобігти витоку клієнтів. Для вирішення проблеми необхідно заповнити певні фрагменти великої моделі даних, і потім допомагаємо вибрати програми, які допоможуть вирішити цю проблему. Це можуть бути дуже нескладні програми, скажімо Excel. Насамперед варто спробувати вирішити основну проблему за допомогою цих інструментів. Намагатися заповнити всю модель відразу, використовувати всі джерела даних буде великою помилкою. Дані в джерелах необхідно ретельно проаналізувати, щоб забезпечити їх якість. Після успішного вирішення однієї-двох проблем першорядної важливості, в ході якого забезпечено якість необхідних для цього джерел даних, можна приступати до вирішення наступних проблем, поступово заповнюючи інші фрагменти моделі даних, а також використовуючи заповнені раніше фрагменти.
В каталозі TAdviser перерахований ряд російських компаній, що мають відношення до постачань і впровадження СГД та надання супутніх послуг. Одночасно варто розуміти, що в ряді великих проектів деякі вендори можуть брати участь безпосередньо, в першу чергу, НР і IBM. Деякі замовники в цьому випадку відчувають себе впевненіше, цілком покладаючись на сервісну підтримку провідних світових виробників. Безумовно, вартість володіння в цьому випадку помітно підвищується.
Тенденції та перспективи
Стрімка еволюція щорічно вносить серйозні зміни в основні тренди розвитку СГД. Так, у 2009 році на перше місце ставилася здатність економічно розподіляти ресурси (Thin Provisioning), останні кілька років проходять під знаком роботи СГД в "хмарах". Спектр пропонованих систем відрізняється різноманітністю: величезна кількість представлених моделей, різні варіанти і комбінації рішень від початкового рівня до Hi-End класу, рішення під ключ і покомпонентно збірка із застосуванням найсучаснішої начинки, програмно-апаратні рішення від російських виробників.
Прагнення до скорочення витрат на ІТ-інфраструктуру вимагає постійного балансу між вартістю ресурсів СГД і цінністю даних, які на них зберігаються в даний момент часу. Для прийняття рішення про те, як найбільш ефективно розміщувати ресурси на програмних і апаратних засобах, фахівці ЦОД керуються не тільки підходами ILM і DLM, а й практикою многоуровнего зберігання даних. Кожній одиниці інформації, що підлягає обробці і зберіганню, присвоюються певні метрики. У їх числі ступінь доступності (швидкість надання інформації), важливість (вартість втрати даних у разі апаратного і програмного збою), період, через який інформація переходить на наступну стадію.
 Приклад поділу систем зберігання відповідно до вимог до зберігання та обробки інформації за методикою багаторівневого зберігання даних.
Приклад поділу систем зберігання відповідно до вимог до зберігання та обробки інформації за методикою багаторівневого зберігання даних.
Разом з тим, зросли вимоги до продуктивності транзакційних систем, що передбачає збільшення кількості дисків в системі і відповідно вибір СГД більш високого класу. У відповідь на цей виклик виробники забезпечили системи зберігання новими твердотільними дисками, переважаючими колишні по продуктивності більш ніж в 500 разів на "коротких" операціях читання-запису (характерних для транзакційних систем).
Популяризація хмарної парадигми сприяла підвищенню вимог до продуктивності і надійності СГД, оскільки в разі відмови або втрати даних постраждають не один-два підключених безпосередньо сервера - відбудеться відмова в обслуговуванні для всіх користувачів хмари. В силу тієї ж парадигми проявилася тенденція до об'єднання пристроїв різних виробників в федерацію. Вона створює об'єднаний пул ресурсів, які надаються на вимогу з можливістю динамічного переміщення додатків і даних між географічно рознесеними майданчиками і постачальниками послуг.
Певне зрушення відзначений у 2011 році в області управління "Великими даними". Раніше подібні проекти перебувай на стадії обговорення, а тепер вони перейшли в стадію реалізації, пройшовши весь шлях від продажу до впровадження.
На ринку намічається прорив, який вже стався на ринку серверів, і, можливо, вже в 2012 році ми побачимо в масовому сегменті СГД, що підтримують Дедуплікація і технологію Over Subscribing. У підсумку, як і в випадку серверної віртуалізації, це забезпечить масштабну утилізацію ємності СГД.
Подальший розвиток оптимізації зберігання полягатиме у вдосконаленні методів стиснення даних. Для неструктурованих даних, на які припадає 80% всього обсягу, коефіцієнт стиснення може досягати декількох порядків. Це дозволить істотно знизити питому вартість зберігання даних для сучасних SSD