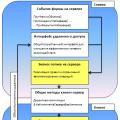
У багатьох з Вас виникають питання щодо створення парсера на PHP. Наприклад, є якийсь сайт і Вам необхідно отримати з нього контент. Я довго не хотів писати цю статтю, оскільки конкретного змісту в ній немає. Щоб зробити парсер на PHP, потрібно знати цю мову. А ті, хто його знає, таке питання просто не поставить. Але в цій статті я розповім, як взагалі створюються парсери, а також, що потрібно вивчати.
Отже, ось список пунктів, які необхідно пройти, щоб створити парсер контенту на PHP:
Відзначу також, що все це зрозуміє і зможе застосувати на практиці тільки той, хто знає PHP. Тому ті, хто його тільки починає вивчати, знадобляться такі знання:
Ті ж, хто ще взагалі не знає PHP, то до парсерів у цьому випадку ще далеко, і потрібно вивчати всю базу. У цьому Вам допоможе
10
сен
Нещодавно мені було поставлене завдання написати php парсер сайту. Поставлене завдання було виконано і завдяки їй з'явилася ця нотатка. До цього я нічого подібного не робив, тож не судіть суворо. Це мій перший парсер php.
І так з чого розпочати вирішення питання "як написати парсер". Давайте спочатку розберемося що це таке. У народі парсер (parser) або синтаксичний аналізатор - це програма яка отримує дані (наприклад веб сторінка), як їх аналізує структурує, робить вибірку і потім проводить якісь операції з ними (пишемо дані в файл, в БД або виводимо на екран) . Це завдання нам необхідно виконати в рамках веб-програмування.
Для замітки я вигадав таке тестове завдання. Потрібно спарсити за певним пошуковим запитом посилання на сайти з перших 5 сторінок видачі і вивести їх на екран. Парсувати я вирішив видачу пошукової системи bing. А чому б не написати парсер яндекса чи гугла запитаєте ви. Такі матері пошукачі мають не кволий захист від парсинго (капча, бан ip, розмітка, що змінюється, куки і тд), і це тема окремої статті. У цьому плані з бінгом таких проблем немає. І тому нам потрібно буде зробити:
- Отримати (спасити) контент html сторінки засобами php
- Отримати дані, що цікавлять нас (а саме посилання)
- Спарсувати посторінкову навігацію та отримати посилання на наступну сторінку
- Знову спарсити сторінку за посиланням, отримати дані, отримати наступне посилання
- Виконати вище описану операцію N кількість разів
- Вивести усі отримані посилання на екран
Спочатку напишемо функцію, потім її розберемо
Function getBingLink($link)( $url="https://www.bing.com/search"; //отримуємо контент сайту $content= file_get_contents($url.$link); //прибираємо висновок помилок libxml_use_internal_errors(true) ; //отримуємо об'єкт класу DOMdocument = new DOMDocument(); >loadHTML($content); //отримуємо об'єкт класу DOMXpath $xpath = new DOMXpath($mydom); //робимо вибірку за допомогою xpath $items=$xpath->query("//*[@class="b_algo" ]/h2/a"); //виводимо в циклі отримані посилання static $a=1; foreach ($items as $item)( $link=$item->
"; $a++; ) )
І так розберемо функцію. Для отримання контенту сайту використовуємо функцію php file_get_contents($url.$link) . До неї підставляємо адресу запиту. Є ще багато методів отримання контенту html сторінки, наприклад, cUrl, але на мій погляд file_get_contents найпростіший. Потім викликаємо об'єкт DOMDocument і таке інше. Це все стандартно і про це можна прочитати в інтернеті детальніше. Хочу акцентувати увагу на методі вибірки потрібних нам елементів. Для цього я використовую xpath. Мою xpath шпаргалку можна глянути. Є й інші методи вибірки, такі як регулярні вирази, Simple HTML DOM, phpQuery. Але на мій погляд краще розібратися з xpath, це дасть додаткові можливості при роботі з XML документами, синтаксис легше ніж з регулярними виразами, на відміну від css селекторів можна знайти елемент за текстом, що знаходиться в ньому. Наприклад прокоментую вираз //*[@class="b_algo"]/h2/a . Детальніше синтаксис можна переглянути в моїй шпаргалці xpath. Ми вибираємо з усієї сторінки посилання, що лежать у тезі h2 у дівці з класом b_algo. Зробивши вибірку, ми отримаємо масив і якого в циклі виведемо на екран усі отримані посилання.
Парсинг посторінкової навігації та отримання посилання на наступну сторінкуНапишемо нову функцію і за традицією розберемо її пізніше
Function getNextLink($link)( $url="https://www.bing.com/search"; $content= file_get_contents($url.$link); libxml_use_internal_errors(true); $mydom = new DOMDocument(); $ mydom->preserveWhiteSpace = false; $mydom->resolveExcelals = false; query("//*[@class="sb_pagS"]/../following::li/a"); foreach ($page as $p)( $nextlink=$p->getAttribute("href"); ) return $nextlink;
Майже ідентична функція змінилася тільки xpath запит. //*[@class="sb_pagS"]/../following::li/a отримуємо елемент з класом sb_pagS (це клас активної кнопки посторінкової навігації), піднімаємось на елемент вгору по дереву дерева, отримуємо перший сусідній елемент li і отримуємо у ньому посилання. Це і є посилання на наступну сторінку.
Парсим видачу N кількість разівПишемо функцію
Function getFullList($link)( static $j=1; getBingLink($link); $nlink=getNextLink($link); if($j
Ця функція викликає getBingLink($link) і getNextLink($link) доки скінчиться лічильник j. Функція рекурсивна, тобто викликає сама себе. Про рекурсію прочитайте докладніше в інтернеті. Зверніть увагу, що $j статична, тобто вона не видаляється при наступному виклику функції. Якби це було не так, то рекурсія була нескінченною. Ще додам з досвіду, якщо хочете пройти всю сторінкову навігацію, то пишіть if умова поки є змінна $nlink. Є ще пара підводного каміння. Якщо парсер працює довго, то це може викликати помилку з-за часу виконання скрипта. Типово 30с. Для збільшення часу на початку файлу ставте ini_set("max_execution_time", "480"); та задавайте потрібне значення. Так само може виникати помилка через велику кількість викликів однієї функції (більше 100 разів). Фіксується відключенням помилки, ставимо на початок скрипта ini_set("xdebug.max_nesting_level", 0);
Тепер нам залишилося написати html форму для введення запиту та зібрати парсер докупи. Дивіться листинг нижче.